

CORTEX-M4F基本知识
发布于2021-05-30 20:17 阅读(1317) 评论(0) 点赞(4) 收藏(3)
文章目录
- 一、ARM Cortex-M4F处理器
- 二、指令系统
- 2.1指令系统简介
- 2.2指令系统——ARM系统架构
- 2.3指令系统——指令简表与寻址方式
- 2.4指令系统——数据传送类指令:取数指令
- 2.5指令系统——数据传送类指令:存数指令
- 2.6指令系统——数据传送类指令:堆栈操作指令
- 2.7指令系统——数据传送类指令:寄存器间数据传送指令
- 2.8指令系统——数据操作类指令:算术运算类指令
- 2.9指令系统——数据操作类指令:逻辑运算类指令
- 2.10指令系统——数据操作类指令:位测试指令
- 2.11指令系统——数据操作类指令:数据序转指令(1)
- 2.12指令系统——数据操作类指令:数据序转指令(2)
- 2.13指令系统——数据操作类指令:扩展类指令
- 2.14指令系统——跳转控制类指令
- 2.15指令系统——其他指令
- 三、汇编语言的基本语法
- 四、指令集与机器码对应表
一、ARM Cortex-M4F处理器
1.1ARM Cortex-M4F处理器简介

- ARM Cortex-M4F是─种低功耗、高性能、高速度的处理器。
- 硬件方面支持除法指令,并且有着中断处理程序和线程两种模式。 在处理中断方面,M4F具有着自动保存处理器状态和回复低延迟中断。
- M4内核的定点运算的速度是M3内核的两倍,而浮点运算速度比M3内核快十倍以上,同时功耗只有一半。
1.2 ARM Cortex-M4F处理器内部结构概要——嵌套中断向量控制器
嵌套中断向量控制器(Nested Vectoredlnterrupt Controller,NVIC)是一个在Cortex M4F中内建的中断控制器。

- 在MSP432系列芯片中,中断源数为64个,优先等级可配置范围为0-7,还可对优先等级进行分组。
- 为优化低功耗设计,在芯片可快速进入超低功耗状态(MSP430),且在超低功耗睡眠模式下可唤醒。
- 包含一个24位倒计时定时器SysTick,即使系统在睡眠模式下也能工作,也为在RTOS同类内核芯片间移植带来便利。
1.3 ARM Cortex-M4F处理器内部结构概要——存储器保护单元
存储器保护单元(Memory Protection Unit ,MPU)是指可以对一个选定的内存单元进行保护。

- 它将存储器划分为8个子区域。
- 子区域的优先级均是可自定义的。
- 处理器可以使指定的区域禁用和使能。
1.4 ARM Cortex-M4F处理器内部结构概要——调试解决方案
对存储器和寄存器进行调试访问。

-
具有SWD或JTAG调试访问接口,或两种都包括。
-
Flash修补和断点单元用于实现硬件断点和代码修补。
-
数据观察点和触发单元用于实现观察点、触发资源和系统分析。
-
指令跟踪宏单元用于提供对printf()类型调试的支持。
-
跟踪端口接口单元用来连接跟踪端口分析仪,包括单线输出模式。
1.5 ARM Cortex-M4F处理器内部结构概要——总线接口
ARM Cortex-M4F处理器提供先进的高性能总线(AHB-Lite)接口,包括的4个接口分别为: ICode存储器接口,DCode存储器接口和系统接口,还有基于高性能外设总线(ASB)的外部专用外设总线(PPB)

-
位段的操作可以细化到原子位段的读写操作。
-
对内存的访问是对齐的。
-
写数据时采用写缓冲区的方式。
1.6 ARM Cortex-M4F处理器内部结构概要——浮点运算单元
-
处理器可以处理单精度32位指令数据。
-
结合了乘法和累积指令用来提高计算的精度。
-
硬件能够进行加减法、乘除法以及平方根等运算操作,同时也支持所有的IEEE数据四舍五入模式。
-
拥有32个专用32位单精度寄存器,也可作为16个双字寄存器寻址。
-
通过采用解耦三级流水线来加快处理器运行速度。
1.7 ARMCortex-M4F处理器存储器映像
存储器映像是指:把这4GB空间当做存储器来看待,分成若干区间,都可安排实际的物理资源。

-
该处理器直接寻址空间为4GB,2^32=4GB,分为8个空间
-
地址范围是:Ox0000_o000~OxFFFF_FFFF。
-
ARM定出的条条框框是粗线条的,它依然允许芯片制造商灵活地分配存储器空间,以制造出各具特色的MCU产品。
-
CM4F的存储器系统支持小端配置和大端配置。—般具体某款芯片在出广时已经被厂广商定义过,例如MSP432采用小端格式。
1.8 ARM Cortex-M4F处理器的寄存器——概要
学习一个CPU,理解其内部寄存器用途是重要一环。

CM4F处理器的寄存器包含:
- 用于数据处理与控制的寄存器。包括:RO~R15,其中R13作为堆栈指针SP。SP 实质上有两个(MSP与PSP) ,但在同一时刻只能有一个可以看到。
- 特殊功能寄存器,有预定义的功能,而且必须通过专用的指令来访问
- 浮点寄存器
ARMCortex-M4F处理器的寄存器——数据处理与控制寄存器
- 大部分能够访问通用寄存器的指令都可以访问R0-R12。其中:低位寄存器(R0~R7)能够被所有访问通用寄存器的指令访问;高位寄存器(R8~R12)能够被所有32位通用寄存器指令访问,而不能被所有的16位指令访问。
- 寄存器R13被用作堆栈指针(SP) ,用于访问堆栈。
- 寄存器R14为子程序连接寄存器(LR)
- 寄存器R15是程序计数寄存器(PC),指向当前的程序地址。
ARMCortex-M4F处理器的寄存器——特殊功能寄存器
- 程序状态字寄存器在内部分为以下几个子寄存器: APSR、IPSR、EPSR。
- 中断屏蔽寄存器的D31~D1位保留,只有D0位(记为PM)有意义。当该位被置位时,除不可屏蔽中断和硬件错误之外的所有中断都会被屏蔽。
- 错误屏蔽寄存器与中断屏蔽寄存器的区别在于它能够屏蔽掉优先级更高的硬件错误异常。
- 基本优先级屏蔽寄存器提供了一种更加灵活的中断屏蔽机制。
- 控制寄存器的D31~D2位保留,D1、D0有意义。
ARM Cortex-M4F处理器的寄存器——浮点寄存器
- 浮点运算时M4F处理器的最大亮点之一,所以浮点寄存器只在Cortex-M4F处理器中存在,其中包含了用于浮点数据处理与状态控制的寄存器。
- 浮点处理寄存器:S0~S31和D0-D15,S0-S31都是32位寄存器,每个寄存器都可用来存放单精度浮点数,它们两两组合可用来存放双精度浮点数两两组合成成双精度寄存器时可用D0-D15来访问。
- 浮点状态控制寄存器:浮点状态控制寄存器提供了浮点系统的应用程序级控制,其包括浮点运算结果的状态信息与定义一些浮点运算的动作。

负标志N
零标志Z
进位/借位标志C
溢出标志V
交替半精度控制位AHP
默认NaN模式控制位DN
清零模式控制位FZ
舍入模式控制位RMode
输入非正常累计异常位IDC
不精确累积异常位IXC
下溢累积异常位UFC
溢出积累异常位OFC
二、指令系统
2.1指令系统简介

2.2指令系统——ARM系统架构
- 在ARM系统中,使用架构(architecture)一词,即体系结构,主要指使用的指令集。
- 同一架构,可以衍生出许多不同处理器型号,比如:ARMv7-M是一种架构型号,其中v7是指版本号,而基于该架构处理器有Cortex-M3、Cortex-M4、Cortex-M4F等。

2.3指令系统——指令简表与寻址方式
指令简表

寻址方式

举例说明:
;立即数寻址
SUB R1,R0,#1 ;R1<一R0-1
MOV R0,#0xff ;立即数0xff装入R0寄存器
;寄存器寻址
MOV R1,R2 ;<一R2
SUB R0,R1,R2 ;0<一R1-R2
;直接寻址
LDR Rt,label ;号label处连续取4字节至寄存器中
LDRH Rt,label ;址label处读取半字到Rt
LDRB Rt,label ;址label处读取字节到Rt
;偏移寻址及寄存器间接寻址
LDR R3,[PC,#100] ;为(PC + 100)的存储器单元的内容加载到寄存器R3中
LDR R3,[R4] ;为R4的存储单元的内容加载到寄存器中
2.4指令系统——数据传送类指令:取数指令
存储器中内容加载(load)到寄存器中的指令(取数指令)

2.5指令系统——数据传送类指令:存数指令
寄存器中内容存储(store)至存储器中的指令(存数指令)

2.6指令系统——数据传送类指令:堆栈操作指令
堆栈(stack)操作指令
- PUSH指令将寄存器值存于堆栈中,最低编号寄存器使用最低存储地址空间,最高编号寄存器使用最高存储地址空间;
- POP指令将值从堆栈中弹回寄存器,最低编号寄存器使用最低存储地址空间,最高编号寄存器使用最高存储地址空间。

堆栈操作指令举例
PUSH {RO,R4-R7} ;将RO,R4~R7寄存器值入栈
PUSH{R2,LR} ;将R2,LR寄存器值入栈
POP{RO,R6,PC} ;出栈值到RO,R6,PC中,同时跳转至PC所指向的地址
2.7指令系统——数据传送类指令:寄存器间数据传送指令
MOV指令:Rd表示目标寄存器;imm为立即数,范围0x00~0xff

2.8指令系统——数据操作类指令:算术运算类指令

算术运算类指令限制条件

2.9指令系统——数据操作类指令:逻辑运算类指令
AND、EOR和ORR指令把寄存器Rn、Rm值逐位与、异或和或操作;BIC指令是将寄存器Rn的值与Rm的值的反码按位作逻辑“与”操作,结果保存到Rd。

ASR、LSL、LSR和ROR指令,将寄存器Rm值由寄存器Rs或立即数imm决定移动位数,执行算术右移、逻辑左移、逻辑右移和循环右移。

2.10指令系统——数据操作类指令:位测试指令

2.11指令系统——数据操作类指令:数据序转指令(1)
该指令用于改变数据的字节顺序。Rn为源寄存器,Rd为目标寄存器,且必须为R0~R7之—。
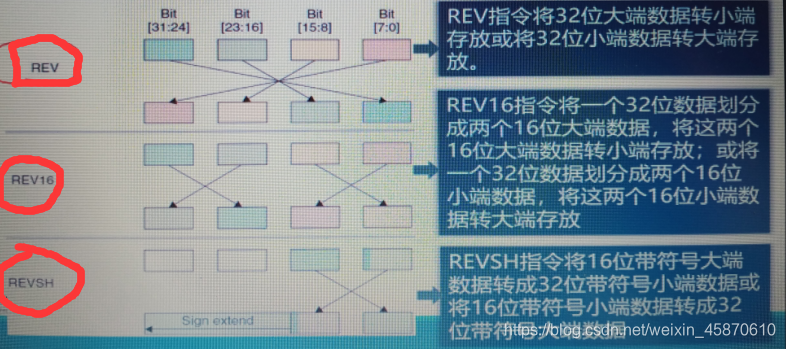
2.12指令系统——数据操作类指令:数据序转指令(2)

2.13指令系统——数据操作类指令:扩展类指令

2.14指令系统——跳转控制类指令

;跳转控制指令举例
BEQ label ;条件转移,标志位Z=1时转移到label
BL funC ;调用子程序funC,把转移前的下条指令地址保存到LR
BX LR ;返回到函数调用处
2.15指令系统——其他指令

三、汇编语言的基本语法
3.1汇编语言的基本语法——汇编语言简介

3.2汇编语言的基本语法——汇编语言格式
- 编语言源程序可以用通用的文本编辑软件编辑,以ASCII码形式存盘。
- 具体的编译器对汇编语言源程序的格式有一定的要求,为了能够正确地产生目标代码以及方便汇编语言的编写,编译器还提供了一些在汇编时使用的命令、操作符号,在编写汇编程序时,也必须正确使用它们。
- 由于编译器提供的指令仅是为了更好地做好“翻译”工作,并不产生具体的机器指令,因此这些指令被称为伪指令。
- 汇编语言源程序以行为单位进行设计,每一行最多可以包含以下四个部分。
标号: 操作码 操作数 注释
3.3汇编语言的基本语法——标号
- 如果一个语句有标号,则标号必须书写在汇编语句的开头部分。
- 可以组成标号的字符有:字母A ~ Z、字母a ~ z、数字0~9、下划线“_”、美元符号“$ ”,但开头的第一个符号不能为数字和$。
- 编译器对标号中字母的大小写敏感,但指令不区分大小。
- 标号长度基本上不受限制,但实际使用时通常不要超过20个字符。若希望更多的编译器能够识别,建议标号(或变量名)的长度小于8个字符。
- 标号后必须带冒号“:”。
- 一个标号在一个文件(程序)中只能定义一次,否则重复定义,不能通过编译。
- 一行语句只能有一个标号,编译器将把当前程序计数器的值赋给该标号。
3.4汇编语言的基本语法——操作码
- 操作码包括指令码和伪指令,其中伪指令是指CCS开发环境ARMCortex-M4F汇编编译器可以识别的伪指令。
- 对于有标号的行,必须用至少一个空格或制表符(TAB)将标号与操作 码隔开。编译器对标号中字母的大小写敏感,但指令不区分大小。
- 对于没有标号的行,不能从第一列开始写指令码,应以空格或制表符 (TAB)开头。
3.5 汇编语言的基本语法——操作数
- 操作数可以是地址、标号或指令码定义的常数,也可以是由伪运算符构成的表达式。
- 若一条指令或伪指令有操作数,则操作数与操作码之间必须用空格隔开书写。
- 操作数多于一个的,操作数之间用逗号“”分隔。操作数也可以是ARM Cortex-M4F内部寄存器,或者另一条指令的特定参数。
- 操作数中一般都有一个存放结果的寄存器,这个寄存器在操作数的最前面。
汇编语言的基本语法——操作数注意点

汇编语言的基本语法——操作数:伪运算符

3.6 汇编语言的基本语法——注释
- 注释即是说明文字,类似于C语言,多行注释以“/”开始,以“/"结束。这种注释可以包含多行,也可以独占一行。
- 在CCS环境的ARMCortex-M4F处理器汇编语言中,单行注释以“#”引导或者用“I/”引导。用“#”引导,“#”必须为单行的第一个字符。
3.7 常用伪指令简介(CCS环境为例介绍)——系统预定义的段
- C语言程序在经过gcc编译器最终生成.elf格式的可执行文件。
- .elf可执行程序是以段为单位来组织文件的。
- 通常划分为如下几个段:.text、.data和.bss,其中,.text是只读的代码区,.data是可读可写的数据区,而.bss则是可读可写且没有初始化的数据区。

3.8 常用伪指令简介——常量的定义
- 使用常量定义,能够提高程序代码的可读性,并且使代码维护更加简单。
- 常量的定义可以使用.equ汇编指令。
- 常量的定义还可以使用.set汇编指令,其语法结构与.equ相同。 例如:


3.9 常用伪指令简介——程序中插入常量
用于程序中插入不同类型常量的常用伪指令:

插入字和字符串常量代码:

3.10 常用伪指令简介——条件伪指令,文件包含伪指令
- .if条件伪指令后面紧跟着一个恒定的表达式((即该表达式的值为真),并且最后要以.endif结尾。中间如果有其他条件,可以用.else填写汇编语句。
- .ifdef标号,表示如果标号被定义,执行下面的代码。
.include "filename"
- .include是一个附加文件的链接指示命令,利用它可以把另一个源文件插入当前的源文件—起汇编,成为一个完整的源程序。
- filename是一个文件名,可以包含文件的绝对路径或相对路径,但建议对于一个工程的相关文件放到同一个文件夹中,更多的时候能使用相对路径。
- .section伪指令:用户可以通过.section伪指令来自定义一个段。例如:
.section .isr vector, "a" @定义一个.isr vector段,"a"表示允许段
- .global伪指令:.global伪指令可以用来定义一个全局符号。例如:
.global symbol @定义一个全局符号symbol
- .extern伪指令: .extern伪指令的语法为: .extern symbol,声明symbol为外部函数,调用时可以遍访所有文件找到该函数并且使用它。
.extern main @声明main为外部函数
bl main @进入main函数
- .align伪指令: .align伪指令可以通过添加填充字节使当前位置满足一定的对齐方式。语法结构为:.align [exp[, fill]],其中,exp为0-16之间的数字,表示下一条指令对齐至2exp位置,若未指定,则将当前位置对齐到下一个字的位置,fill给出为对齐而填充的字节值,可省略,默认为0x00。
.align 3@把当前位置计数器值增加到23的倍数上,若已是23的倍数,不做改变
- .end伪指令: .end伪指令声明汇编文件的结束。
四、指令集与机器码对应表
4.1指令集与机器码对应表——如何找到机器码
-
第一步生成.Ist文件
需要在集成环境里对工程进行设置,让它能够生成.lst文件,在本书里集成环境为ccs。也可对于汇编和C/C++工程编译生成.lst文件。
-
第二步记录,找规律
将指令按照正确的格式给变量赋值,写入main函数中编译,编译结束后查看main.o.lst文件,找到指令对应的十六进制机器码,进行记录
-
第三步确定机器码
每个变量注意取不同的值,多次进行编译记录,然后找出规律,确定每个变量变化所改变的机器码的部分。至此就可以完全确定这个指令所对应的机器码。




原文链接:https://blog.csdn.net/weixin_45870610/article/details/117327185
所属网站分类: 技术文章 > 博客
作者:美丽的老婆你听我说
链接:http://www.phpheidong.com/blog/article/86889/d27b6f495c2e74e64a14/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力