

阿里云贾扬清:大数据+AI工程化,让数据从「成本」变为「资产」
发布于2021-05-30 20:22 阅读(1069) 评论(0) 点赞(10) 收藏(0)
简介: 近年来,数字经济发展迅速,企业转型背后频频涌现「数字力量」的身影。云计算、大数据、人工智能的快速融合形成了数字经济的新基建,也为数字经济发展带来了新的机遇。
5 月 20 日,阿里巴巴副总裁、阿里云计算平台负责人贾扬清在媒体沟通会做了《科技创新时代的数字力量》演讲,本文对其演讲内容做了精简编辑,以飨读者。

01 科技创新时代的数字力量
我们先来认识一家建筑公司。
说建筑公司的原因是,每一次工业革命往前升级、向前发展的背后,最重要的其实是现有行业怎么革新自己的生产力。建筑行业是非常典型的一个例子,今天说了那么多大数据和 AI,到底能给他们带来什么样的价值?
这家公司叫中建三局一公司,是国家基建中的核心力量,一直以建筑速度跟效率著称。
30 多年以前,1985 年,就以「三天一层楼」建造了深圳第一座超高层地标性建筑、当时「中国高楼之最」——深圳国贸大厦。
1996 年,又以「九天四个结构层」的速度缔造了当时亚洲第一、世界第四高楼——深圳地王大厦,将中国建筑业从一般超高层推向可与世界摩天大楼相媲美的领先水平。
放眼全国乃至世界,都有他们的作品,承建了非常多我们耳熟能详的标杆性建筑 :国家体育馆(鸟巢)、央视新址 CCTV 大楼…… 除了地标性建筑,他们还建了机场、地铁、高速、医院(雷神山医院)、学校(清华美院)、办公大楼(阿里腾讯新浪移动等办公大楼)……
中建三局一公司高效的建筑能力,给我们带来非常大的价值。
几十年过去了,建筑设计变得越来越新,砖瓦结构变成了钢筋混凝土结构,中建三局一公司对建筑行业的理解也一直在向前发展。30 多年前,他们依靠人与时间的赛跑;如今,他们依靠数据的流动。去年,中建三局一公司联手阿里云,共同建设数据中台。
造一座高楼,有非常多的物质在流转,从一粒沙子到砖头、玻璃、钢筋、螺丝、各种工程机械,怎么让它们更高效地流转起来,是建筑公司都会遇到的问题。不仅如此,他们还需要考虑怎样提升建造工艺、提升创新的建筑方法,以及通过数字化能力,来管理建筑过程、建筑物料等一系列问题。
阿里云基于一站式数据开发和综合治理平台 DataWorks 打造的数据中台,为中建三局一公司建设了一个「数字孪生体」,用数据和算法来预测,何时补沙子、何时调配工程机械,以及做其他运营管理方面的事情。
今天,我们看到,中国整个建筑市场有 10 万家建筑公司,除了中建三局一公司这种大型的标杆企业,还有很多中小型的建筑公司,从业人员共有 5000 余万。帮助这些中小型企业从传统的、小作坊式的、刀耕火种的模式变成像中建三局一公司那样,是阿里云希望在数据方面做的一些事情。
我们相信把阿里云数据中台建设的核心能力,和各行各业的专业知识结合起来之后,可以帮助更多企业,就像中建三局一公司一样实现数字化转型。
02 「一体两面」,助力企业用好数据
虽然每个人都在提大数据,每个人也都觉得自己在用大数据,但其实谁也不知道大数据到底该怎么用。
阿里云打造了一系列将数据用起来的「武器」,希望通过云上数据综合治理及智能化,赋予企业数字力量。
企业经常面临的挑战是,建了很多零碎的数据系统,表格、Word、照片、视频等异构数据存在 Excel、数据仓库等不同的数据库里,最后成为「数据孤岛」。
因此,企业在建设数据中台时,经常会在技术、业务、组织三方面遇到挑战。技术上,数据怎么打通;业务上,不同口径的数据如何总结;组织上,怎么把存放在不同地点的数据统一管理起来。
商业公司经常遇到的一个挑战是——算收入会面临财务、证监会等各种各样的不同口径,运营同学需要去看不同情况的营业额,这些最后都会下沉到一句 SQL 语言或者一个数据任务上。这些任务如果不一致,最后就会出现数据的不一致,结果的不一致,口径的不一致,都是一系列问题。
从技术角度来讲,我们逐渐构建了一套完整的数据处理体系,叫「一体两面」。
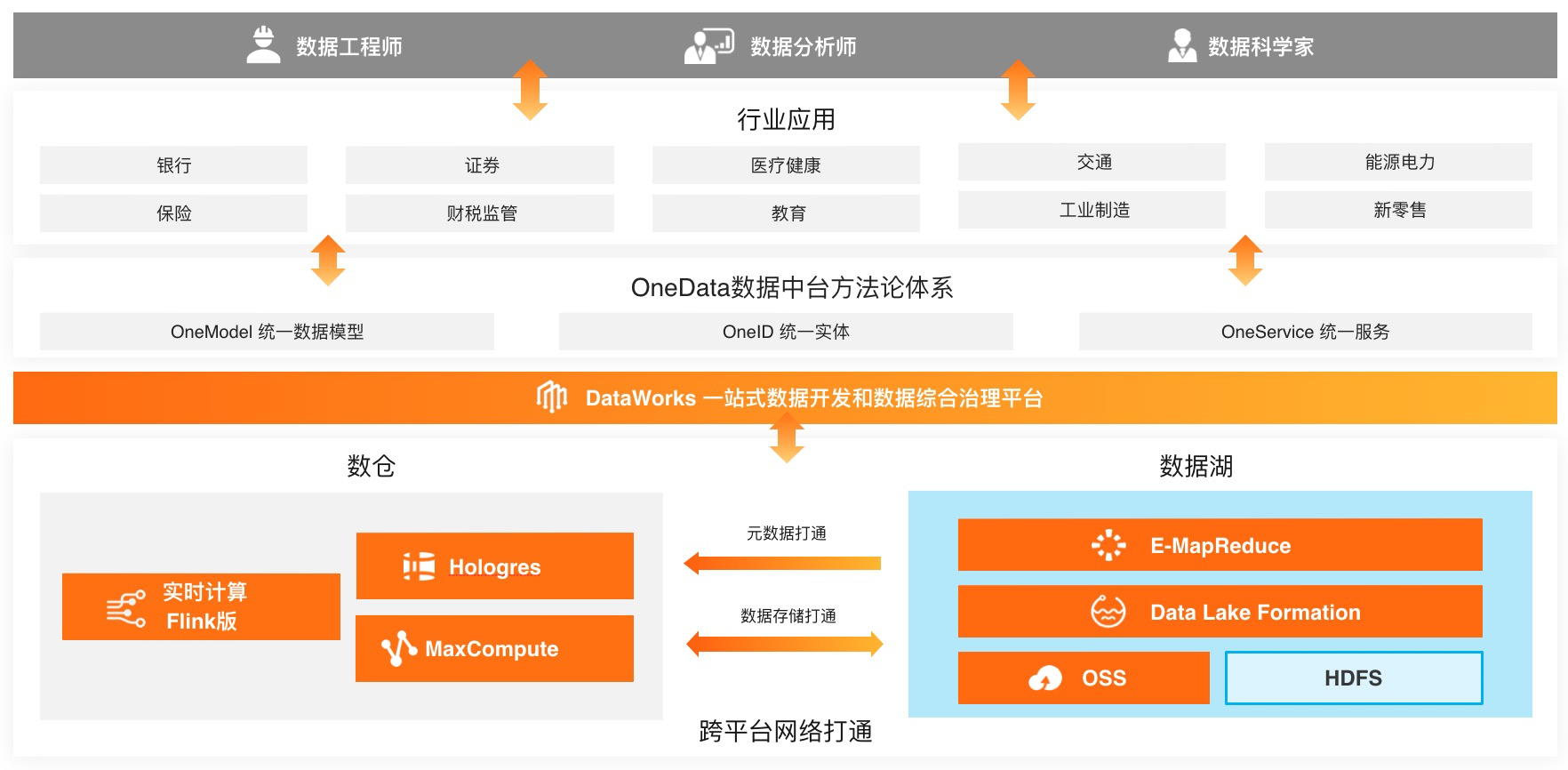
「一体」是指一体化的数据开发和数据综合治理平台 DataWorks,各种各样的行业应用都基于这个平台搭建。
DataWorks 迄今为止已经累积了约 8 万名用户。每天阿里大概有 1/4 的员工在 DataWorks 上做数据开发和应用。
一体化的开发平台下,有两种不同的数据组织形态——数据仓库和数据湖,即所谓「两面」。
「数据仓库」的概念很早以前就有了,可以将其理解为一个巨大的 Excel 表格或者一堆巨大的 Excel 表格。阿里很早以前就建了自己的数据仓库 MaxCompute,它是「飞天」的重要组成部分之一,已经沉淀了非常好的大规模数据仓库能力 。
在 MaxCompute 的演进过程中,对数据进行实时分析的需求诞生了。比方说,双 11 时,促销策略要根据用户的购买行为进行及时调整。于是,几年前,我们开发了一套实时计算引擎 Flink。Flink 最开始是由德国一个团队做的,现在阿里巴巴和德国团队一起,继续把 Flink 作为一个开源的流计算实施标准往前推进。
以前,我们只是对数据进行总结,出报表;但越来越多的数据开始需要实时的服务,比方说「猜你喜欢」,既需要实时化,也需要对用户的历史行为做实时分析,然后迅速对相关产品做服务。
前几年开始,我们在「T+1」计算的离线数仓基础上,做了实时数仓 + 服务一体化的应用——交互式分析产品 Hologres,它在双 11 支撑了非常多的实时决策。淘宝、天猫的决策层可以通过 Hologres 实时看到每一个商品品类在每一个地区的实时的销售额情况,当发现销售额 / 触达率与预期不一致时,可以及时调整策略。
随着异构数据越来越多,在我们做各种服务的时候,不再是表格那么精准的数据呈现形式,可能是像日志(log)的形式,这些图片、视频、语音等数据形态对传统的数据仓库来说就不是那么合适了。记得我们 2013 年在谷歌刚开始做机器学习的时候,把一堆图片存在了数据仓库里,结果发现,所有图片都是一堆字符串,看不见图片的内容。
于是,「数据湖」的概念兴起了。先不着急把数据都存成 Excel 表格,该是 Word 就是 Word,该是图片就是图片,该是视频就是视频,不管数据来源和格式,先把这些数据都放到一个湖里。
但业务数据,有些存在湖里,有些存在仓里,怎么合起来统一做分析和处理?去年,我们提出「湖仓一体」,在传统的数据湖和数据仓库上建一个数据中台。
这对于创新业务来说,没什么问题。但现有非常多的企业,本身已经有数据仓库了,那如何把已有的资源利用起来?
我们在技术侧做了很多工作。通过最底层的存储资源、计算资源的打通,让大家能够更加容易地从数据仓库的角度存取数据湖里的信息,或者在数据湖上构建一系列开源引擎,同时分析数据湖和数据仓库里的数据。
03 AI 加持,挖掘数据的价值,变「成本」为「资产」
管好数据的同时,我们发现,数据量越来越大,数据的单位价值越来越低。
因此,我们开始思考,怎么挖掘数据的价值,帮助企业创新业务、提高效率,将数据从成本变成资产。
AI 可以让数据更加智能。AI 算法不只能做数据的总结,还可以做分析和决策。
但并不是所有的企业都具备将 AI 变为生产力的能力,为自己所用。Gartner 的调查研究发现,只有 53% 的项目能够从人工智能(AI)原型转化为生产。AI 要成为企业生产力,就必须以工程化的技术来解决模型开发、部署、管理、预测、推理等全链路生命周期管理的问题。
我们总结发现,AI 工程化领域有三大亟待推进的事情:数据和算力的云原生化,调度和编程范式的规模化,开发和服务的标准化普惠化。
第一,从供给角度看,AI 工程化是数据和算力的云原生化。
智能时代是靠数据和算力来驱动的。无论是计算机视觉、自然语言处理,还是其他的 AI 系统,都与数据量密不可分。
上世纪九十年代,手写体邮政编码已经在用 AI 识别,那时用来训练 AI 模型的数据量仅有 10M 左右。阿里与清华大学不久前合作发布的超大规模中文多模态预训练模型 M6,是用 2TB 图像、300GB 语料数据预训练而成的。今天,在产业界,训练一个 AI 模型需要的数据量通常会更大。
OpenAI 曾做过一个统计,从 2012 年做出 AlexNet,到 2018 年 DeepMind 做出 AlphaGo Zero,对于计算量的需求增长了约 30 万倍。

根据摩尔定律,每 18 个月,CPU 单核的计算能力就会增长一倍。但 2008 年前后,摩尔定律就开始「失效」,算力的增速开始逐渐变缓。
可以看到,随着数据量越来越大,模型变得越来越精准、高效且复杂,无论是在数据还是计算方面,都需要有一个更大规模、更大体量的底座,来支撑上层 AI 的需求。而云计算能够在数据和算力上提供更强的支持。
第二,从核心技术的角度看,AI 工程化是调度和编程范式的规模化。
因为大规模、大体量底座的背后,往往面临两个成本问题:
一个是资源的成本。训练一个大模型,往往需要一堆 GPU 来做大规模计算。英伟达最新的 DGX-2,售价大概在一台 20 万美元,真的贵。OpenAI 训练模型大概需要 512 块 GPU、64 台机器。如果搭一个专门用来做大规模训练的集群,可能是小一个亿的成本。这个时候,如果跑去跟公司、研究院或者跟政府说,我需要一个亿,就是为了搭一个集群,这个集群就是为了训练一个模型,这个模型拿来还不知道怎么用,我得先训练出来看看。这显然是很麻烦的事情。
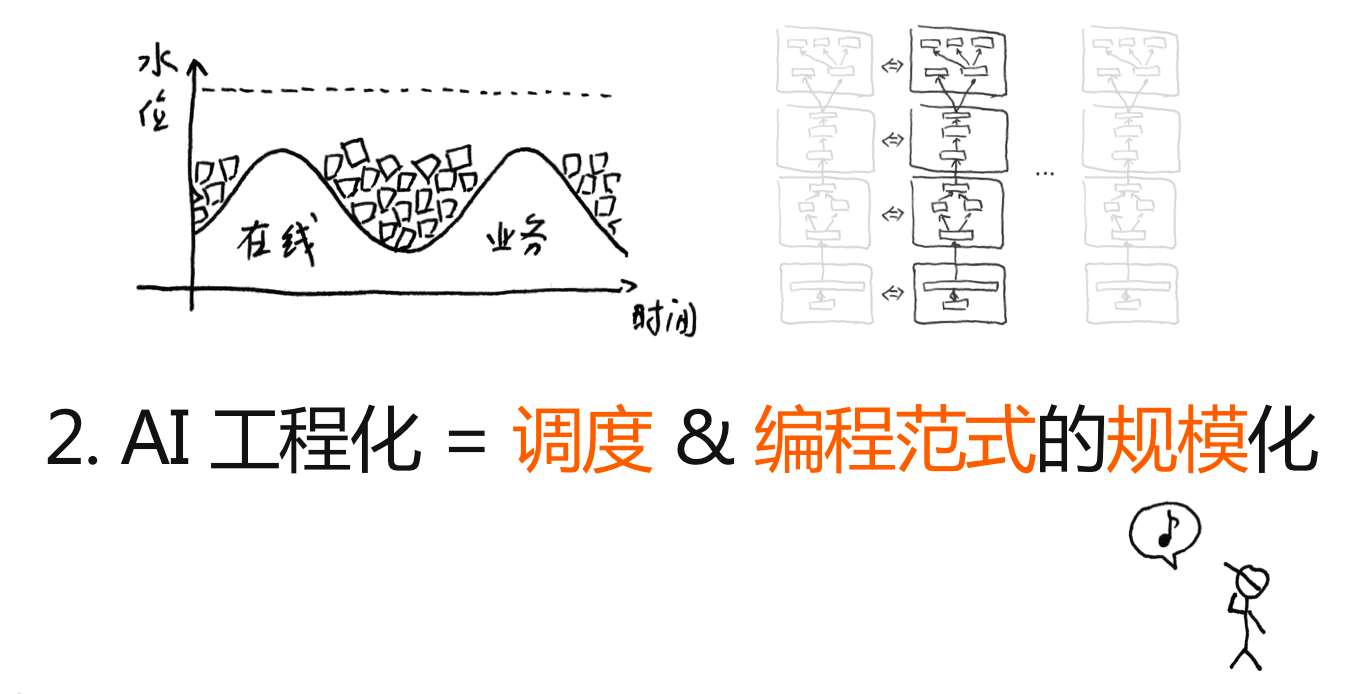
管理大规模的集群和大规模的系统,需要用到非常典型的「削峰填谷」方法,考验我们是否能够把 AI 计算任务掰开、揉碎,变成一小块一小块的任务,部署在资源空闲的机器上。这背后是一个巨大的训练任务,AI 工程师需要做非常多的工作。
我们在训练 M6 模型的时候没有买新的机器,就是在现有的生产集群上面,利用「潮汐效应」,把计算量提出来,用来训练模型。
另一个是人的成本。AI 没有 SQL 那么清晰干净的、以目标导向的框架,比如,写一句 SQL,就能驱动 MaxCompute 等计算引擎拉一堆机器来做运算;AI 也不像在线服务一样,可以实现非常简单的、一台机器和几台机器的简单复制,机器间不需要交互,操作简单。
AI 程序要在各种各样的机器、资源之间(GPU 与 GPU 间,或 GPU 与 CPU 间)捣腾数据,要把一个算法(一个数学公式)放到参数服务器上,告诉机器 A 何时与机器 B 说话,机器 B 何时与机器 C 说话,并且最好是快一点。于是,AI 工程师就得写一堆无比复杂、很多人看不懂的代码。
AI 工程师都听说过数据并行、模型并行等概念,这些概念下需要有一个相对简单的软件编程范式,让我们更加容易把集群以及计算的需求切片,把 Computer 跟 Communication 比较好地分配。但是编程范式今天还没有达到一个让彼此都很好理解的程度。因此,人力成本非常高。
也就是说,在大量的数据和算力基础上,一个非常明显的需求是如何更好地做到资源调度和资源调配,以及如何让工程师更容易撰写分布式编程范式,特别是如何来规模化,这是 AI 工程化的第二个体现。
我们设计了一个相对简单、干净的编程框架 Whale,让开发者能够更容易地从单机的编程范式跳到分布式的编程范式。比如,只需告诉 Whale,将模型分为 4 个 stage,Whale 就会自动把这些 stage 放到不同的机器上去做运算。
第三,从需求或者出口的角度看,AI 工程化是开发和服务的标准化、普惠化。
AI 做了非常多有意思的模型,为了使这些模型能够更加紧密地应用在实际场景中,还需要很多工作。但并不是每个人都有时间来学习 AI 如何建模,如何训练和部署等。
所以,我们一直在思考,如何让大家更容易上手这些高大上的 AI 技术。

阿里云机器学习平台 PAI 团队,基于阿里云 IaaS 产品,在云上构建了一个完整的 AI 开发全生命周期的管理体系,从最开始写模型,到训练模型,到部署模型。其中,Studio 平台提供可视化建模,DLC 平台(Deep Learning Container)提供云原生一站式的深度学习训练,DSW 平台(Data Science Workshop)提供交互式建模, EAS 平台(Elastic Algorithm Service )提供更简易、省心的模型推理服务。我们的目标是,希望 AI 工程师能在几分钟之内就开始写第一行 AI 代码。

迄今为止,阿里云通过大数据、AI 平台已经服务了各行各业的客户,宝钢、三一集团、四川农信、太平洋保险、小红书、VIPKID、斗鱼、亲宝宝等。我们希望通过我们的大数据和 AI 能力,给企业提供升级的动力。
本文为阿里云原创内容,未经允许不得转载。
原文链接:https://blog.csdn.net/yunqiinsight/article/details/117331932
所属网站分类: 技术文章 > 博客
作者:匿名哭哭
链接:http://www.phpheidong.com/blog/article/86811/5d4fb62d026fd1c1cfae/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力