

都2021年了,不会还有人连深度学习不了解吧(一)- 激活函数篇
发布于2021-05-30 19:48 阅读(1369) 评论(0) 点赞(23) 收藏(1)
一、前言
本人目前研一,研究方向为基于深度学习的医学图像分割,转眼间已接触深度学习快1年,研一生活也即将结束,期间看了大量的英文文献,做了大量的实验,也算是对深度学习有了一个初步的了解吧。接下来的一段时间,我会以总结的形式来记录研一期间学到的关于深度学习的基础知识,其中穿插着大量的个人作深度学习方面工作的经验,写这个系列的初衷一方面是为了记录研一的学习成果,另一方面也是为了帮助更多的人了解到深度学习这一大热领域,最后,大喊一声:深度学习yyds!
二、激活函数介绍
在接触激活函数之前,我们需要大致了解一下什么是感知机。
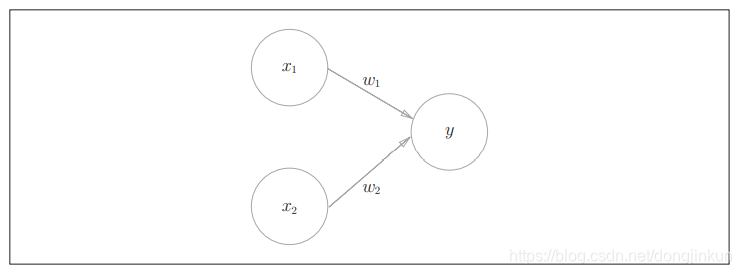
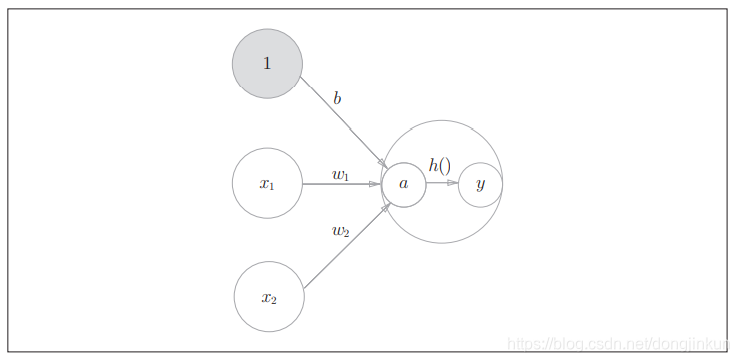
上图中的感知机接受x1和x2两个输入信号,输出为y。若用数学公式来表达图中的感知机,则:
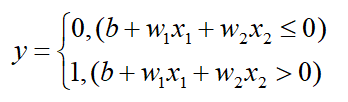
b是称为偏置,用于控制神经元被激活的容易程度;而w1和w2是表示各个信号的权重的参数,用于控制各个信号的重要性。感知机将x1、x2、1(偏置,图中未画出)三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过0,则输出1,否则输出0。
我们将上述公式写为更简洁的形式:
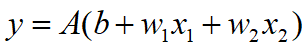
输入的总和会被函数A转换,转换后的值就是输出y。在输入总和超过0时返回1,否则返回0。从公式中可以看出,该步骤可以分为2个阶段,先计算输入信号的总和,然后用激活函数转换。因此,可以将上述公式改写为:
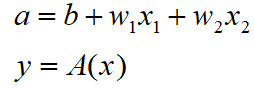
刚才登场的A(x)会将输入信号转换为输出信号,这种函数称为激活函数(activation function)。激活函数的作用在于决定如何来激活输入信号的总和。至此,相信大家已经对激活函数有了一个大致的了解,明确激活函数的任务是什么,下面我们介绍一下常用的激活函数有哪些。
三、常用的激活函数
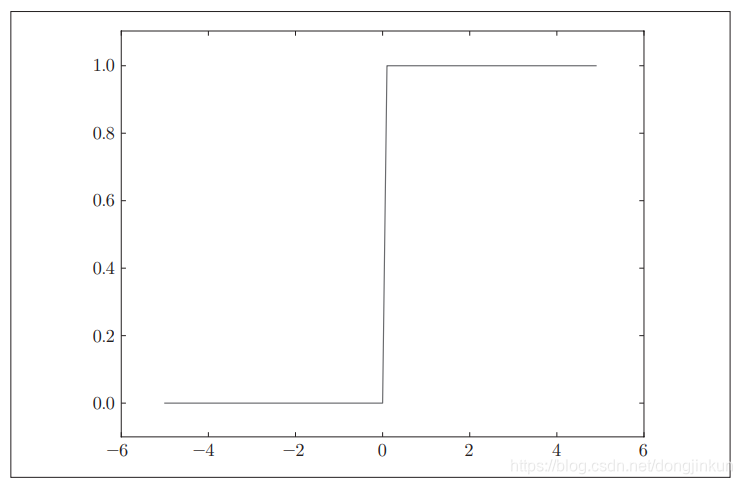
3.1 阶跃函数
从图中可以清晰地看出,阶跃函数以0为界,输出从0切换为1(或者从1切换为0)。它的值呈阶梯式变化,所以称为阶跃函数。
3.2 Sigmoid函数
Sigmoid函数定义为:
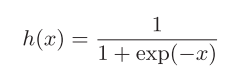
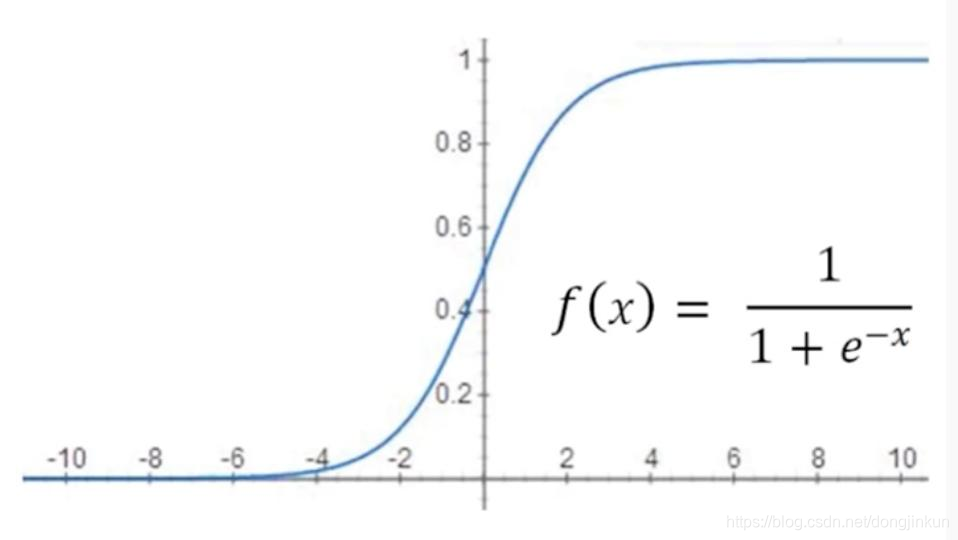
Sigmoid函数图像如下图所示:
Note:(Sigmoid函数和阶跃函数的比较)
- 1.首先注意到的是“平滑性”的不同。sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义。
- 2.另一个不同点是,相对于阶跃函数只能返回0或1,sigmoid函数可以返回0.731 …、0.880 …等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是0或1的二元信号,而神经网络中流动的是连续的实数值信号。
- 3.共同点:实际上,两者的结构均是“输入小时,输出接近0(为0);随着输入增大,输出向1靠近(变成1)”。也就是说,当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0到1之间。
3.3 tanh函数
tanh是双曲函数中的一个,tanh()为双曲正切。
tanh函数定义为:
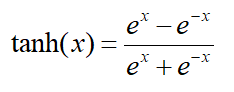
图像如下所示:
Note(很重要):
Sigmoid函数和tanh函数作为常用的激活函数,必定有其的优势所在,但是两者都存在致命的缺陷,尤其是在越来越深的网络表现得愈加明显。首先,我们需要了解为什么深度神经网络收敛慢的原因。
这是因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
也可以通过两者得图像可以看到,当输入大于2时,梯度会变得越来越小(更加详细的解读请移步详细解读BN的本质),这会导致深度神经网络出现梯度弥散的问题,以至于深度神经网络模型不能收敛。而之后提出的ReLU函数很好的解决了这个问题。
3.4 ReLU函数
3.4.1 ReLU介绍
ReLU函数定义如下式所示:
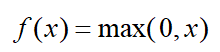
ReLU图像如下图所示:
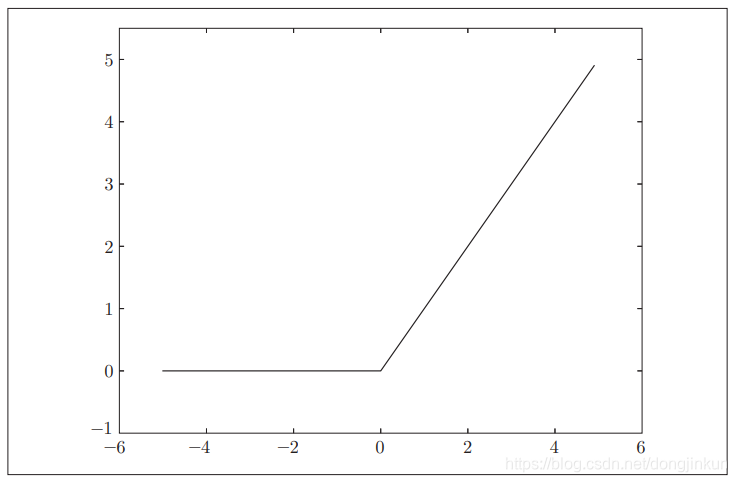
3.4.2 使用ReLU的优势
第一个优点是 ReLU 函数计算简单,可以提升模型的运算速度,加快模型的收敛速度;第二个是如果网络很深,会出现梯度消失的问题,使得模型会出现不会收敛或者是收敛速度慢的问题,而使用 ReLU函数可以有效的解决模型收敛速度慢的问题。
四、 为什么使用激活函数
首先,我们需要明确一点是神经网络的中激活函数必须使用非线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深网络层数就没有什么意义了。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。为了具体地理解这一点,我们来思考下面这个简单的例子。这里我们考虑把线性函数 h(x) = cx 作为激活函数,把y(x) = h(h(h(x)))的运算对应3层经网络A。这个运算会进行y(x) = c × c × c × x的乘法运算,但是同样的处理可以由y(x) = ax(注意,a = c**3)这一次乘法运算(即没有隐藏层的神经网络)来表示。如本例所示,使用线性函数时,无法发挥多层网络带来的优势。因此,为了发挥叠加层所带来的优势,激活函数必须使用非线性函数。
五、激活函数的一些变体
这里只介绍现代神经网络中最常用的ReLU函数的几种变体,变体有很多,包括Leaky ReLU、PReLU、ELU等等,说实话,我在这接近一年研究深度学习的工作中,从未用过ReLU的任何变体,而且同门师兄弟也没听说谁用过,所以在这里只是简单的介绍。
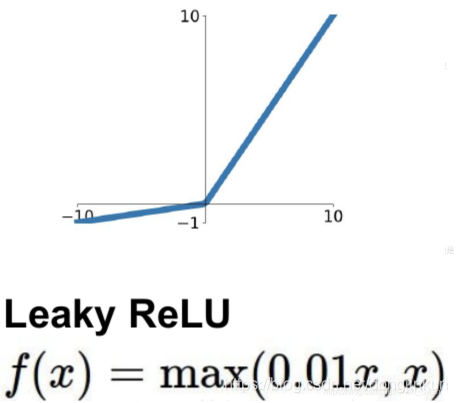
5.1 Leaky ReLU
为什么提出了Leaky ReLU?这需要从ReLU说起,ReLU函数对正数样本原样输出,负数直接置零。在正数不饱和,在负数硬饱和,ReLU在负数区域被Kill(即直接置0这一操作)的现象叫做dead relu。为了解决上述的dead ReLU现象。这里选择一个数,让负数区域不在饱和死掉。这里的斜率都是确定的,即Leaky ReLU。Leaky ReLU的定义及图像如下所示:
5.2 PReLU
PReLU与Leaky ReLU类似,只不过ReLU的参数是一个可学习的参数,而Leaky ReLU的参数是一个定值。PReLU的定义如下:
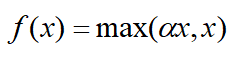
原文献建议初始化alpha,alpha为0.25,不采用正则,但是这要根据具体数据和网络,通常情况下使用正则可以带来性能提升。与Relu比起来,PRelu收敛速度更快。
参考文献
《深度学习入门-基于Python的理论与实现》
《ImageNet Classification with Deep ConvolutionalNeural Networks》
计划 – 深度学习系列
都2021年了,不会还有人连深度学习还不了解吧?(一)-- 激活函数篇
都2021年了,不会还有人连深度学习还不了解吧?(二)-- 卷积篇
都2021年了,不会还有人连深度学习还不了解吧?(三)-- 损失函数篇
都2021年了,不会还有人连深度学习还不了解吧?(四)-- 上采样篇
都2021年了,不会还有人连深度学习还不了解吧?(五)-- 下采样篇
都2021年了,不会还有人连深度学习还不了解吧?(六)-- Padding篇
都2021年了,不会还有人连深度学习还不了解吧?(七)-- 评估指标篇
都2021年了,不会还有人连深度学习还不了解吧?(八)-- 优化算法篇
都2021年了,不会还有人连深度学习还不了解吧?(九)-- 注意力机制篇
都2021年了,不会还有人连深度学习还不了解吧?(十)-- 数据归一化篇
觉得写的不错的话,欢迎点赞+评论+收藏,这对我帮助很大!

原文链接:https://blog.csdn.net/dongjinkun/article/details/117163273
所属网站分类: 技术文章 > 博客
作者:Nxnndn
链接:http://www.phpheidong.com/blog/article/86698/e98e055df3d8c28e129c/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力