

你想知道的手势识别都在这里
发布于2021-05-30 19:39 阅读(934) 评论(0) 点赞(23) 收藏(1)
基于YOLO+ResNet50的手势识别
(一)项目背景以及系统环境
本文所使用的深度学习框架为pytorch-gpu-1.7.1版本,python3.7版本,需要在特定的系统环境中运行。本文搭建实验所需要的系统环境如下所示。
1.1 项目背景
近年来,计算机视觉技术蓬勃发展,为生产和生活带来了巨大的变革。像是刷脸支付、无人驾驶等已经上市或即将走向成熟的技术,极大便利了我们的日常生活。但是我们观察到,目前市场上尚未出现一款完善的针对会议演示控制的计算机视觉产品。同时,由于新冠疫情的影响,加深了人们对于非接触式交互的需求,人们迫切需要一款非接触式的人机交互系统,来解决传统以键鼠为代表的接触式交互带来的卫生隐患。于是,为了填补这一大市场漏洞,我们团队研究并开发出了这一款基于手势识别的会议控制系统,借此提高会议的操作便利性和直观性。
1.2 硬件环境
系统最低配置要求:
GPU:GTX 550Ti(不支持A卡); CPU:i3三代及以上。
推荐配置:
GPU:GTX 1050Ti及以上(不支持A卡);CPU:i3五代及以上。
1.3 操作系统
实验平台所使用的操作系统为windows10。安装的支持库只要有python3.7,OpenCV-Python以Pytorch-gpu-1.7.1版本。
1.4 主要界面

1:程序调用默认摄像头。
2:确保开始时,用户手臂处于放松状态,程序将通过人物的位置自动确定基准参数,如:起始左右手锁定、人物起始位置、动作启动线等。
3:通过算法,程序实时追踪手的位置和特征状态并和对左右手的区分,并将结果实时反馈给预测对象。手离开动作起始线(即图中横线)后开始捕获动作轨迹,再次回到起始线下后输出预测结果到终端。
4:也可以设置控制模式,可以选择进行对PPT和图片管理器的操作(详情参考演示视频)。

1.5 开发工具
开发工具:
| 硬件信息表 | ||
|---|---|---|
| 硬件名称 | 规格 | 用途 |
| 摄像头 | 杂牌720P | 获取视频流 |
| 影驰显卡 | GTX1660 骁将 | 提供算力 |
| CPU | I3-9100F | 完成预测 |
| 软件信息表 | ||
|---|---|---|
| 软件名称 | 版本 | 说明 |
| Python | 3.7 | 主要运行环境 |
| JDK | 1.8 | 实现预测输出 |
| Pytorch | 1.7.1 | 算法使用框架 |
| CUDA | 11.0 | 提供GPU指令集架构 |
算法技术:
| 模型 | 作用 |
|---|---|
| YoloV3 | 目标检测v1.0 |
| YoloV5s | 目标检测v2.0 |
| MoblieNetV3_YoloV5s | 目标检测v3.0 |
| Resnet50 | 特征提取 |
(二)前期准备
2.1 前言
深度学习是一种通过大量数据不断的学习从而能够对未知数据进行检测识别的技术。因此为使手势识别模型能够自动及有效地对手势进行识别,需要先对手数据采取大量的高质量的数据,以便能够得到良好的识别模型。我们使用Yolo模型对目标进行检测,再从检测的结果的基础上使用ResNet50模型对手的二十一点进行特征的提取,再根据输出的二十一点的坐标进行手势的判断。
2.2 数据集准备
本项目所采集的手为会议场景下的基本手势。Yolo模型的数据集使用LabelImg工具进行标识图片。
Resnet模型的数据集使用开源项目的数据集https://codechina.csdn.net/EricLee/handpose_x进行训练。
2.3 Yolo数据集的标注
【数据标注】
本文采用的YoloV3算法是一种监督式学习方法,因此需要对输入到Yolo网络的图像数据进行标注即添上对应的标签,并且还需要满足该网络对图像数据格式的要求。本文使用LabelImg工具完成对手图像数据的标注工作,标注示意图如下图所示。
 注意文件路径不要有中文!!
注意文件路径不要有中文!!
【标注文件】
在使用LabelImg工具对手进行图像数据进行标注时,会生成.xml文件。其内容如下所示。
<annotation>
<folder>JPEGImages</folder>
<filename>0-19.jpg</filename>
<path>D:\data\JPEGImages\0-19.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>624</width>
<height>832</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Hand</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>384</xmin>
<ymin>241</ymin>
<xmax>426</xmax>
<ymax>286</ymax>
</bndbox>
</object>
</annotation>
在使用LabelImg工具对手进行标注而生成的.xml文件中记录的内容如上所示。其中‘folder’标识所在文件夹的名称;‘filename’表示手图像的名称;‘path’表示手语图像数据存放的路径;‘size’表示图像的大小和深度;‘object’中的name为目标物体;最后的‘bndbox’存放的是边框坐标信息。示例中目标物体Hand的坐标信息为(384,241) (426,286),其中前者表示边框的左上角坐标信息,后者代表边框的右下边的坐标信息。
2.4 ResNet50数据集
【数据标记】
本次手部关键点使用https://codechina.csdn.net/EricLee/handpose_x提供的数据集进行训练。
【标注文件】
{
“maker”: “Eric.Lee”,
“date”: “2021-02-01”,
“info”: [{“bbox”: [0.0,0.0,0.0,0.0],
“pts”: {
“0”: {“x”: 78,“y”: 95},“1”: {“x”: 72,“y”: 82},“2”: {“x”: 65,“y”: 72},
“3”: {“x”: 59,“y”: 69},“4”: {“x”: 55,“y”: 55},“5”: {“x”: 59,“y”: 65},
“6”: {“x”: 38,“y”: 69},“7”: {“x”: 36,“y”: 72},“8”: {“x”: 38,“y”: 72},
“9”: {“x”: 55,“y”: 72},“10”: {“x”: 36,“y”: 80},
“11”: {“x”: 38,“y”: 84},“12”: {“x”: 42,“y”: 91},
“13”: {“x”: 55,“y”: 82},“14”: {“x”: 36,“y”: 90},
“15”: {“x”: 40,“y”: 97},“16”: {“x”: 44,“y”: 99},
“17”: {“x”: 55,“y”: 93},“18”: {“x”: 40,“y”: 97},
“19”: {“x”: 42,“y”: 103},“20”: {“x”: 46,“y”: 103}}}]
}
首先非常感谢作者Eric.Lee辛苦做的训练集并开源分享出来,对此表示由衷的感谢。"maker"就是数据集的作者;"date"制作的日期;"info"中的"pts"里面的数据就是手部的二十一个关键点的坐标。
(三)Yolo V3
简介
Yolo (You Only Look Once)。
【Darknet-53】
Yolo V3 采用了 Darknet-53 的网络结构(含有 5 组残差模块)来提取特征。其网络结构采用了横纵交叉结构,并采用了连串的 3×3 和 1×1 卷积。其中, 3×3 的卷积增加通道数,而 1×1 的卷积在于压缩 3×3 卷积后的特征表示,同时 Darknet-53 为了防止池化带来的低级特征的丢失,采用了全卷积层,并且引 入了 residual 结构。这意味着网络结构可以更好地利用 GPU,从而使其评估效率更高、速度更快。Darknet-53 作为特征提取层,最终每个预测任务得到的特 征大小为 [3×(4+1+C)]。每个 grid cell 预测 3 个预测框,4 代表 4 是边界框中心坐标 bx,by,以及边界框 bw,bh,1 代表预测值,C 代表预测类别。最终 YoloV3 可以获取(16×10+32×20+64×40)个特征向量
【网络结构】
模型结构如下图:

3.1 模型训练
由于训练数据集仅有1000张左右,担心数据量较少不足以支撑模型的训练,因此通过对数据集进行左右与上下镜像处理来增强训练数据集,运行数据处理文 件后,得到数据增强后的图片共4000张左右。
训练过程batch_size设置为8,初始learn_rate设置为1e-3。主干特征提取网络中,冻结训练可以加快训练速度,也可以在训练初期防止权重被破坏,所以我们的 Init_Epoch起始世代设置为0,Freeze_Epoch冻结训练世代设置为50。训练完一个Epoch之后,batch_size设置为4,将初始learn_rate设置为1e-4, Init_Epoch 起始世代设置为50,Freeze_Epoch冻结训练世代设置为100。
下图为三次训练后保存的模型文件,最终的Total_Loss在2.2左右。
从此可以看出loss收敛在2附近,考虑到继续训练可能会产生过拟合现象,训练完三次之后,停止训练。训练结束,得到最终的检测模型。

3.2 模型测试
通过测试集上测试模型的检测效果,如下图所示。

从上图可以看出检测效果非常好,训练好的模型可以准确识别出不同图片,不同形状的手。

选取了一些光线不足,噪点增加,目标被遮挡以及目标在复杂环境的图像进行测试,分析算法的环境适用性,如上图所示。在上图中,可以看出在灰暗环境,复杂背景的情况下,算法在不良条件环境下也可以做出正确的判断。
3.3 结果分析
【FPS】
在用摄像头进行测试中发现FPS在20-30之间。还是比较快的检测速度。

【mAP】
通常使用mAP来评估检测准确率,mAP的值越大,证明检测效果越好,在本次实验中,因为检测目标只有手这一类物体,因此在数值上,mAP的值等于AP值,AP值为召回率(ReCall)与准确率(Precision)所围成的R-P曲线面积;使用原YoloV3算法对同一数据集进行一次训练,对比三次检测检测的效果如下图所示。

由于在测试结果中,发现第三次的模型存在比较严重的过拟合现象,所以使用第二次训练的模型。
(四)ResNet50
在上述YoloV3完成手的检测后,需要对手进行单手二十一个特征点提取,即可对具体的手势进行判断,在实际会议中,并非每个人的手都在操作,即摄影设备的手势识别是一个开放集上的手势识别问题,其本质是度量学习。必须知道是哪一部分的人在进行手势操作。我们以ResNet50为基本框架对单手二十一点进行特征提取,采用Wing_Loss对训练过程进行监督,使得模型的识别具备较高类间可分性与类内紧凑性。
Wing loss的手部关键点检测算法,该方法利用级联回归方法以及转换机制,通过级联两个卷积神经网络,利用第一阶段产生的形状向平均形状转换得到的转换矩阵,进而将手部图片进行转换,第二阶段减小手部姿态对关键点检测的影响。为了能够利用全手的特征信息,同时平衡误差对关键点的影响提出了wing loss函数,兼顾大小误差对手部关键点准确性的影响。
Wingloss函数如下
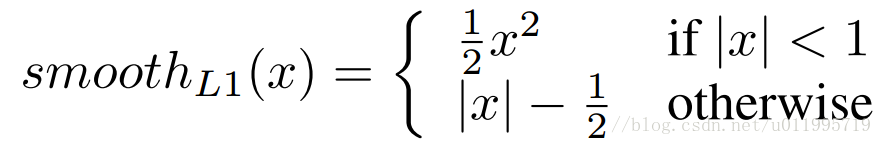

4.1模型训练
【网络结构】

在神经网络中,残差网络可以在不影响网络性能的前提下解决梯度消失和梯度爆炸这两个问题。
残差网络通过加入ShortCutConnections,变得更易于优化。ResNet50是一个性能优良的残差网络模型,它包含49个卷积层和1个全连接层。
在ResNet50残差网络模型下,对比分析不同数量级的学习率对验证集正确率的影响,可以得到如下结论:
⑴ 学习率lr在过大的时候(lr=1e-2),损失函数难以收敛,导致误差较大,验证集的准确率在80%附近剧烈波动。
⑵ 学习率lr在过小的时候(lr=1e-4),损失函数在逐渐收敛,但是收敛速度太慢。
⑶ 当选择学习率lr=1e-3,则损失函数值收敛比较迅速。
通过以上分析我们最终选择学习率lr=1e-4。
4.2模型测试

在上述测试中我们可以看出,ResNet50对于手的特征提取还是十分有效的,只要能检测出目标,就能高效提取出手的特征。
4.3结果分析
下图为ResNet50训练的Loss结果。

我们可以发现最终的MeanLoss和BestLoss都在逐渐收敛于0.099左右。虽然可以不断迭代下取,使得模型对特征的提取效果更加显著,但考虑到GPU算力, 时间以及其他问题,我们便到此停止训练ResNet50的模型。
(五)YoloV5
5.1简介
2020年4月23日YoloV4发布,2020年6月10日YoloV5发布。YoloV4对YoloV3的各个部分都进行了很多的整合创新,而YoloV5则是对YoloV4的细节进行优化。在本次实验中初始的目标检测模型是使用YoloV3,但由于YoloV3的检测效果的精度在复杂环境下稍有不足,例如当目标被遮挡时,虽然能检测出目标,当还是由于精度不高的问题,影响了后续手势的判断,以至我们的模型从YoloV3更改为YoloV5,并对YoloV5模型进行主干网络的换取,以便后续的ResNet50能更好提取特征。
【网络结构】
YoloV5的结构与YoloV4很相似,但是还有细节上的区别。
5.2 输入端
5.2.1 Mosaic数据增强。
V5的输入端沿用了V4的Mosaic数据增强的方式,通过随机缩放,随机剪裁,随机排布的方式进行拼接,对于小目标检测的效果有明显提高。
5.2.2 自适应锚框计算
在传统的Yolo算法中,针对不同的数据集,都会有初始设定的长宽的秒框,那么在网络训练中,网络在初始锚框的基础上输出预测框,进而与真实框进 行对比,计算两者差距,再反向传播,迭代网络参数。V5对于V3、V4再这方面并不是固定的,而是将这个功能嵌入到了代码当中,每次训练中,都会自适 应计算不同训练集中最佳的锚框值。
5.2.3 自适应图片缩放
在V5中对这方面进行了改进,首先是计算出缩放系数,原始图片的长宽都乘以最小的缩放系数,得到原本需要填充的高度。再对32(V5的网络经过5次 下采样,而2的5次方=32。所以至少要去掉32的倍数)取余,得到像素点,再除以2,即得到图片高度两端需要填充的数值通过这种简单的改进,推理速度得 到了37%的提升
5.3Backbone
5.3.1 Focus结构
V3、V4中并没有Focus结构,Focus结构是V5模型的一个创新点。其中关键点就是进行切片操作。比如下图的切片操作。

5.3.2 CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。v5与v4不同点在于,v4中只有主干网络使用了CSP结构。而v5中设计了两 种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

与yolov3的残差结构对比的话。
CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:
主干部分继续进行原来的残差块的堆叠
另一部分则像一个残差边一样,经过少量处理直接连接到最后。(Part 2)
因此可以认为CSP中存在一个大的残差边。(Part1)
5.3.3Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也 进行了调整。

上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取,在(a)里面是传统的特征金字塔结构,在完成特征金字塔从 下到上的特征提取后,还需要实现(b)中从上到下的特征提取。
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力
5.4输出端
5.4.1 Bounding Box 损失函数
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。
先计算两个框的最小闭包区域面积 (同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
图片理解如下

两个框的最小闭包区域面积 = 红色矩形面积
IoU = 黄色框和蓝色框的交集 / 并集
闭包区域中不属于两个框的区域占闭包区域的比重 = 蓝色面积 / 红色矩阵面积
GIoU = IoU - 比重
5.4.2nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。
5.5模型训练
5.5.1第一次训练情况

第一次训练结果

在上图中我们可以看出,上方的八个指标都在不断收敛于某一个值,但还是还没停止收敛,在测试集中的表现如下

左图为原始的标签文件的显示,右边为第一次的预测结果。可以看出虽然大部分的目标都已经检测出来了,但是精度还是不足。于是我们进行了第二次的训练。
5.5.2第二次训练情况

在上方的八张图,我们可以看出,在缩小范围的情况下,还是在波动,还没完全收敛,但是已经有了收敛迹象,在这里不得不提V5模型的数据增强
如下图所示。

通过数据增强,我们可以增加数据量,有益于防止过拟合现象。但是由于数据还没有完全收敛,所以我们就有了第三次的训练。
5.5.3第三次训练情况

第三次的训练结果,由于在训练到中途发现过拟合现象,并且马上停止训练。
由于中途停止并没有生成相关曲线,所以开启摄像头在明亮、灰暗、被遮掩的环境下进行测试,效果呈现不错。

测试的过程中,我们发现速度方面,V5s的检测速度十分优秀。

(六)YoloV5优化
6.1简介
6.1.1 模型假设


【模型优化】
介于YoloV5的轻便小巧的特点,我们的优化方案是将V5小巧的优点继续发扬,将原生V5中的网络结构替换成MoblieNetV3。在mobilenet中,会有深度可分 离卷积(depthwise separable convolution)由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map。相比常规的卷积操作,其参数 数量和运算成本比较低。
【深度可分离卷积】
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
6.2 DC与PC
6.2.1逐通道卷积(Depthwise Convolution)
DC的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。一张5×5像素、三通道彩色输 入图片(shape为5×5×3),DC首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所 以一个三通道的图像经过运算后生成了3个Feature map。
DC完成后的Feature map数量与输入层的通道数相同,但无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,并没有有效的利用不同 通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature Map。
6.2.2逐点卷积(Pointwise Convolution)
PC的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组 合,生成新的Feature map。有几个卷积核就有几个输出Feature map。经过PC之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
6.3模型测试
【模型测试】
对改模型进行测试之后发现其检测模型非常轻量,只有不到5M的模型。我们从最初的四百兆到现在的不到五兆,我们通过对模型不断的压缩,以便后续的 适配移动端设备。虽然模型的简化了,但是我们也发现精度没有之前的高效,所以也引发了我们的后续思考,有可能是新测试的数据的问题,也有可能是优化模 型之后导致特征丢失的问题。我们将在后续不断进行完善,使得网络在轻量的情况下,精度也能跟上。
(七) 结语
这是我们团队的参加第十二届服务外包与创新创业大赛的题目(A12),然而并没有晋级,虽然很遗憾,但是这半年来,我们收获了很多,测试到凌晨四点,改网络,改文档改到头秃。
也感谢每一位团队小伙伴的辛苦付出。
现在是大二,虽然学长安慰我们说除了ACM其他都是水赛,但是我们还是很希望拿奖,也希望明年决赛答辩现场能有我们的位置。
原文链接:https://blog.csdn.net/weixin_45304503/article/details/117308306
所属网站分类: 技术文章 > 博客
作者:美丽的老婆你听我说
链接:http://www.phpheidong.com/blog/article/86657/03c576f3b3cfd458fd5b/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力