

原来大厂的MySQL面试会问这些问题!
发布于2021-03-14 05:48 阅读(1491) 评论(0) 点赞(28) 收藏(4)
1. 写出下面2个PHP操作Mysql函数的作用和区别(新浪网技术部)
mysql_num_rows() mysql_affected_rows()
这两个函数都作用于 mysql_query($query)操作的结果,
mysql_num_rows() 返回结果集中行的数目。
mysql_affected_rows() 取得前一次 MySQL 操作所影响的记录行数。
mysql_num_rows()仅对 SELECT 语句有效,要取得被 INSERT,UPDATE 或者 DELETE 查询所影响到的行的数目,用 mysql_affected_rows()。
相关题目:取得查询结果集总数的函数是?
mysql_num_rows()
2. sql语句应该考虑哪些安全性?(新浪网技术部)
防止 Sql 注入,对特殊字符进行转义、过滤或者使用预编译的 sql 语句绑定变量。
最小权限原则,特别是不要用 root 账户,为不同的类型的动作或者组建使用不同的账户。当 sql 运行出错时,不要把数据库返回的错误信息全部显示给用户,以防止泄露服务器和数据库相关信息。
3. 简单描述mysql中,索引,主键,唯一索引,联合索引的区别,对数据库的性能有什么影响(从读写两方面)(新浪网技术部)
索引是一种特殊的文件(InnoDB 数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
普通索引(由关键字 KEY 或 INDEX 定义的索引)的唯一任务是加快对数据的访问速度。普通索引允许被索引的数据列包含重复的值。如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字 UNIQUE 把它定义为一个唯一索引。也就是说,唯一索引可以保证数据记录的唯一性。
主键,是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识 一条记录,使用关键字 PRIMARY KEY 来创建。
索引可以覆盖多个数据列,如像 INDEX(columnA, columnB)索引,这就是联合索引。索引可以极大的提高数据的查询速度,但是会降低插入、删除、更新表的速度,因为在执行这些操作时,还要操作索引文件。
4. 有一个留言板,用mysql做数据库,用户信息包括:用户名,密码,email,留言内容包括:留言ID,标题,内容,发表时间,状态(审核,未审核)(新浪网技术部)
请实现下列需求:
(1). 数据库结构。无需写建表语句,用类似下面的表格,描述清楚即可,注意,要在索引栏 中注明是否需要创建索引,以及要创建的索引的类型
| 表名 | table_aaa | ||
|---|---|---|---|
| 字段名 | 字段说明 | 字段类型 | 索引 |
| name | 姓名 | varchar(64) | 唯一索引 |
| gender | 性别 | enum(‘M’,‘F’) |
(2). 用一个 sql 语句查询出发表留言数量大于 10 条的用户名及其留言数量,查询结果按文章数量降序排列参考答案:
用户表结构如下:
| 表名 | user | ||
|---|---|---|---|
| 字段名 | 字段说明 | 字段类型 | 索引 |
| user_id | 用户编号 | int unsigned | 主键 |
| name | 用户名 | varchar(30) | |
| password | 密码 | char(32) | |
| 邮箱 | varchar(50) |
留言表结构如下:
| 表名 | message | ||
|---|---|---|---|
| 字段名 | 字段说明 | 字段类型 | 索引 |
| message_id | 留言编号 | int unsigned | 主键 |
| title | 标题 | varchr(100) | |
| content | 内容 | text | |
| user_id | 用户 id | int unsigned | 普通索引 |
| pubtime | 发表时间 | int unsigned | |
| state | 状态 | tinyint 0 未审核 1 审核 |
查询语句如下:
SELECT u.name, COUNT(*) AS total
FROM user AS u INNER JOIN message AS m ON u.user_id = m.user_id
GROUP BY u.name HAVING total > 10 ORDER BY total DESC
5. 如何用命令把mysql里的数据备份出来(酷讯PHP工程师笔试题)
(1). 导出一张表
mysqldump -u 用户名 -p 密码 库名 表名 > 文件名(如 D:/a.sql)
(2). 导出多张表
mysqldump -u 用户名 -p 密码 库名 表名 1 表名 2 表名 3 > 文件名(如D:/a.sql)
(3). 导出所有表
mysqldump -u 用户名 -p 密码 库名 > 文件名(如 D:/a.sql)
(4). 导出一个库
mysqldump -u 用户名 -p 密码 -B 库名 > 文件名(如 D:/a.sql)
6. 两张表city表和province表。分别为城市与省份的关系表。
city:
| id | city | provinceid |
|---|---|---|
| 1 | 广州 | 1 |
| 2 | 深圳 | 1 |
| 3 | 惠州 | 1 |
| 4 | 长沙 | 2 |
| 5 | 武汉 | 3 |
province:
| id | province |
|---|---|
| 1 | 广东 |
| 2 | 湖南 |
| 3 | 湖北 |
(1). 写一条sql语句关系两个表,实现:显示城市的基本信息。 显示字段:城市id ,城市名, 所属省份 。如:
id(城市 id) cityname(城市名)privence(所属省份)
……
SELECT c.id AS id,c.city AS cityname,p.province
FROM city c LEFT JOIN province p ON c.provinceid=p.id
(2). 如果要统计每个省份有多少个城市,请用groupby 查询出来。 显示字段:省份id ,省份名,包含多少个城市。
SELECT p.id,p.province,count(c.id) AS num
FROM province p LEFT JOIN city c ON p.id = c.provinceid GROUP BY p.id;
7. MySQL数据库中的字段类型varchar和char 的主要区别是什么?哪种字段的查找效率要高,为什么?
区别一,定长和变长
char 表示定长,长度固定,varchar表示变长,即长度可变.当所插入的字符串超出它们的长度时,视情况来处理,如果是严格模式,则会拒绝插入 并提示错误信息,如果是宽松模式,则会截取然后插入。如果插入的字符串长度小于定义长度时,则会以不同的方式来处理,如char(10),表示存储的是10个字符,无论你插入的是多少,都是10个,如果少于10个,则用空格填满。而varchar(10),小于10个的话,则插入多少个字符就存多少个。varchar怎么知道所存储字符串的长度呢?实际上,对于varchar 字段来说,需要使用一个(如果字符串长度小于255)或两个字节(长度大于255)来存储字 符串的长度。
区别之二,存储的容量不同
对 char 来说,最多能存放的字符个数 255,和编码无关。而 varchar 呢,最多能存放65532 个字符。VARCHAR的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是65,532字节
最大有效长度是 65532 字节,在 varchar 存字符串的时候,第一个字节是空的,不存任何的数据,然后还需要两个字节来存放字符串的长度。所以有效长度就是 65535 -1 - 2= 65532 由字符集来确定,字符集分单字节和多字节
Latin1 一个字符占一个字节,最多能存放65532 个字符GBK 一个字符占两个字节, 最多能存 32766 个字符UTF8 一个字符占三个字节, 最多能存 21844 个字符
注意,char 和 varchar 后面的长度表示的是字符的个数,而不是字节数。
两相比较,char 的效率高,没有碎片,尤其更新比较频繁的时候,方便数据文件指针的操作。但不够灵活,在实际使用时,应根据实际需求来选用合适的数据类型。
相关题目:若一个表定义为 create table t1(c int, c2 char(30), c3 varchar(N)) charset=utf8; 问
N 的最大值又是多少?(65535 - 1 - 2 - 4 - 30 * 3 )/3
8. IP该如何保存?
最简单的办法是使用字符串(varchar)来保存,如果从效率考虑的话,可以将ip 保存为整型(unsigned int),使用 php 或 mysql 提供的函数将 ip 转换为整型,然后存储即可。
PHP 函数:long2ip()和 ip2loang()
MySQL 函数:inet_aton()和 inet_ntoa
9. 设有成绩表如下所示,试查询两门及两门以上不及格同学的平均分。
| 编号 | 姓名 | 科目 | 分数 |
|---|---|---|---|
| 1 | 张三 | 数学 | 90 |
| 2 | 张三 | 语文 | 50 |
| 3 | 张三 | 地理 | 40 |
| 4 | 李四 | 语文 | 55 |
| 5 | 李四 | 政治 | 45 |
| 6 | 王五 | 政治 | 30 |
#创建一个成绩表
CREATE TABLE grade(
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, name VARCHAR(10) NOT NULL,
subject VARCHAR(10) NOT NULL, score TINYINT UNSIGNED NOT NULL
);
#插入记录
INSERT INTO grade(name,subject,score) VALUES('张三','数学',90); INSERT INTO grade(name,subject,score) VALUES('张三','语文',50); INSERT INTO grade(name,subject,score) VALUES('张三','地理',40); INSERT INTO grade(name,subject,score) VALUES('李四','语文',55); INSERT INTO grade(name,subject,score) VALUES('李四','政治',45); INSERT INTO grade(name,subject,score) VALUES('王五','政治',30);
#查询语句
SELECT name,AVG(score),SUM(score<60) AS gk FROM grade
GROUP BY name HAVING gk>=2;
10. 为了记录足球比赛的结果,设计表如下,
team:参赛队伍表
| 字段名称 | 类型 | 描述 |
|---|---|---|
| teamID | int | 主键 |
| teamname | varchar(20) | 队伍名称 |
match:赛程表
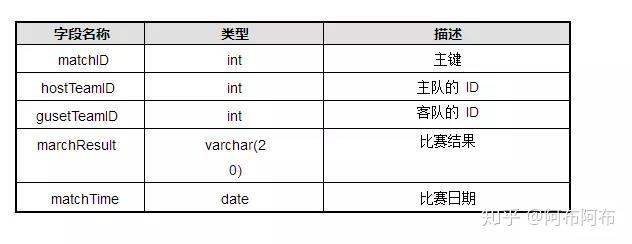
其中,match 赛程表中的 hostTeamID 与 guestTeamID 都和 team 表中的 teamID 关联,查出2006-6-1 到 2006-7-1 之间举行的所有比赛,并且用以下形式列出:
拜仁 2:0不莱梅 2006-6-21
#创建参赛队伍表CREATE TABLE team(
teamID INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, teamName VARCHAR(30) NOT NULL
);
#向参赛队伍表中插入记录
INSERT INTO team(teamName) VALUES(' 拜 仁 '); INSERT INTO team(teamName) VALUES(' 不 莱 梅 '); INSERT INTO team(teamName) VALUES('皇家马德里'); INSERT INTO team(teamName) VALUES('巴塞罗那'); INSERT INTO team(teamName) VALUES(' 切 尔 西 '); INSERT INTO team(teamName) VALUES(' 曼 联 '); INSERT INTO team(teamName) VALUES('AC 米 兰 '); INSERT INTO team(teamName) VALUES('国际米兰');
#创建 match 赛程表
CREATE TABLE mat(
matchID INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEy,
hostTeamID INT UNSIGNED NOT NULL, guestTeamID INT UNSIGNED NOT NULL,
matchResult VARCHAR(20) NOT NULL, matchTime DATE NOT NULL
);
#向赛程表中插入几条记录
INSERT INTO mat(hostTeamID,guestTeamID,matchResult,matchTime) VALUES(1,2,'3:1','2006-6-15');
INSERT INTO mat(hostTeamID,guestTeamID,matchResult,matchTime) VALUES(3,4,'2:2','2006-6-28');
INSERT INTO mat(hostTeamID,guestTeamID,matchResult,matchTime) VALUES(5,6,'0:2','2006-7-10');
INSERT INTO mat(hostTeamID,guestTeamID,matchResult,matchTime) VALUES(7,8,'5:3','2006-5-30');
#查询语句
SELECT t1.teamName,matchResult,t2.teamName,matchTime FROM mat LEFT JOIN team AS t1
ON hostTeamID = t1.teamID LEFT JOIN team AS t2
ON guestTeamID = t2.teamID
WHERE matchTime BETWEEN '2006-6-1' AND '2006-7-1';
11. 有如下两张表a和b,请写出得到结果表的查询语句

a表
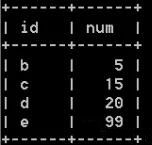
b表
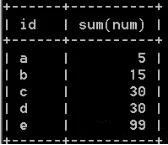
结果表
#创建表 a
a 表b 表结果表
CREATE TABLE t1_uni( id CHAR(1),
num TINYINT
)engine=MyISAM charset=utf8;
#创建表 b
CREATE TABLE t2_uni( id CHAR(1),
num TINYINT
)engine=MyISAM charset=utf8;
#向 a 表中插入记录
INSERT INTO t1_uni VALUES('a',5),('b',10),('c',15),('d',10);
#向 b 表中插入记录
INSERT INTO t2_uni VALUES('b',5),('c',15),('d',20),('e',99);
#查询语句
SELECT id,SUM(num) FROM(
SELECT id,num FROM t1_uni UNION ALL
SELECT id,num FROM t2_uni) AS tmp GROUP BY id;
12. 写出发贴数最多的十个人名字的 SQL,利用下表:members(id,username,posts,pass,email)
SELECT members.username FROM members ORDER BY posts DESC LIMIT 10;
13. 请简述项目中优化sql语句执行效率的方法,从哪些方面,sql语句性能如何分析?
-
尽量选择较小的列
-
将where中用的比较频繁的字段建立索引
-
select子句中避免使用‘*’
-
避免在索引列上使用计算、not in 和<>等操作
-
当只需要一行数据的时候使用limit 1
-
保证单表数据不超过200W,适时分割表。
针对查询较慢的语句,可以使用explain 来分析该语句具体的执行情况。
14. SQL中LEFTJOIN的含义是______,如果tbl_user记录了学生的姓名(name)和学号(ID),tbl_score记录了学生(有的学生考试以后被开除了,没有其记录)的学号(ID)和考试成绩(score)以及考试科目(subject),要想打印出各个学生姓名及对应的的各科总成绩,则可以用SQL语句_______。
left join 表示左外连接,以左表为准,左表中的记录都会出现在查询结果中,如果对应的记录在右表中没有匹配的记录,则右表的字段值以 NULL 填充。
#创建表 tbl_user
CREATE TABLE tbl_user( id INT NOT NULL,
name VARCHAR(50) NOT NULL, PRIMARY KEY (id)
);
#创建表 tbl_socre
CREATE TABLE tbl_score( id INT NOT NULL,
score DEC(6,2) NOT NULL,
subject VARCHAR(20) NOT NULL
);
#插入记录
INSERT INTO tbl_user (id, name) VALUES (1, 'beimu'); INSERT INTO tbl_user (id, name) VALUES (2, 'aihui');
INSERT INTO tbl_score (id, score, subject) VALUES (1, 90, '语文'); INSERT INTO tbl_score (id, score, subject) VALUES (1, 80, '数学'); INSERT INTO tbl_score (id, score, subject) VALUES (2, 86, '数学'); INSERT INTO tbl_score (id, score, subject) VALUES (2, 96, '语文');
#查询语句
SELECT a.id,SUM(b.score) AS sumscore FROM tbl_user a LEFT JOIN tbl_score b ON a.id=b.id
GROUP BY a.id;
15. 使用php 写一段简单查询,查出所有姓名为“张三”的内容并打印出来表 user
| name | tel | content | date |
|---|---|---|---|
| 张三 | 13333663366 | 大专毕业 | 2006-10-11 |
| 张三 | 13612312331 | 本科毕业 | 2006-10-15 |
| 张四 | 021-55665566 | 中专毕业 | 2006-10-15 |
请根据上面的题目完成代码:
$mysql_db=mysql_connect("local","root","pass"); mysql_select_db("DB",$mysql_db);
$result=mysql_query("select * from user where name='张三'");
while($row=mysql_fetch_array($result)){
echo $row['name']. $row['tel']. $row['content']. $row['date']; echo "<br>";
}
16. 写出SQL语句的格式:插入,更新,删除(卓望) 表名 user
| name | tel | content | date |
|---|---|---|---|
| 张三 | 13333663366 | 大专毕业 | 2006-10-11 |
| 张三 | 13612312331 | 本科毕业 | 2006-10-15 |
| 张四 | 021-55665566 | 中专毕业 | 2006-10-15 |
(a). 有一新记录(小王13254748547高中毕业2007-05-06)请用SQL语句新增至表中
(b). 请用sql语句把张三的时间更新成为当前系统时间
(c). 请写出删除名为张四的全部记录
INSERT INTO user(name,tel,content,date)VALUES('小王','13254748547','高中毕业','2007-05-06');
UPDATE user SET date = date_format(now(),'%Y-%m-%d') WHERE name = '张三' DELETE FROM user WHERE name = '张四'
17. 数据库中的事务是什么?
事务(transaction)是作为一个单元的一组有序的数据库操作。如果组中的所有操作 都成功,则认为事务成功,即使只有一个操作失败,事务也不成功。如果所有操作完成,事 务则提交,其修改将作用于所有其他数据库进程。如果一个操作失败,则事务将回滚,该事 务所有操作的影响都将取消。ACID 四大特性,原子性、隔离性、一致性、持久性。
18. What's the difference between mysql_fetch_row() and mysql_fetch_array()?(Yahoo)
mysql_fetch_row() 从和指定的结果标识关联的结果集中取得一行数据并作为数组返回。每个结果的列储存在一个数组的单元中,偏移量从 0 开始。
mysql_fetch_array() 是 mysql_fetch_row() 的扩展版本。除了将数据以数字索引方式储存在数组中之外,还可以将数据作为关联索引储存,用字段名作为名。
mysql_fetch_array() 中可选的第二个参数 result_type 是一个常量,可以接受以下值:
MYSQL_ASSOC,MYSQL_NUM 和 MYSQL_BOTH。其默认值是MYSQL_BOTH。
如果 用了 MYSQL_BOTH , 将 得到一个 同时包 含关联和 数字索 引的数组 。 用MYSQL_ASSOC 只得到关联索引(如同 mysql_fetch_assoc() 那样)用 MYSQL_NUM 只得到数字索引(如同 mysql_fetch_row() 那样)。
19. 请写出php连mysql连接中,获取下一个自增长id值的方法,可以写多个(酷讯)
方法一,使用 show table status ,然后获取 auto_increment 的值
方法二,使用 select max(id) + 1 from table
方法三,如果是刚插入记录,可以使用 last_insert_id() + 1 获得
20. 从表login中选出name字段包含admin的前10条结果所有信息的sql语句(酷讯)
SELECT * FROM login WHERE name LIKE ‘%admin%’ LIMIT 10;
21. 表中有ABC三列,用SQL语句实现:当A列大于B列时选择A列,否则选择B列,当B 列大于 C 列时选择 B 列否则选择 C 列。
使用case语句,如下:
SELECT CASE WHEN A > B THEN A ELSE B END, CASE WHEN B > C THEN B ELSE C END FROM table
22. 写出三种以上MySQL数据库存储引擎的名称(提示:不区分大小写)
MyISAM、InnoDB、BDB(Berkeley DB)、Merge、Memory(Heap)、Example、Federated、Archive、CSV、Blackhole、MaxDB 等等十几个引擎。
23. 请简述数据库设计的范式及应用。
一般第 3 范式就足以,用于表结构的优化,这样做既可以避免应用程序过于复杂同时也避免了 SQL 语句过于庞大所造成系统效率低下。
第一范式:若关系模式 R 的每一个属性是不可再分解的,且有主键,则属于第一范式。第二范式:若 R 属于第一范式,且所有的非主键属性都完全函数依赖于主键属性,则满足第二范式。
第三范式:若 R 属于第二范式,且所有的非主键属性没有一个是传递函数依赖于候选主键属性,则满足第三范式。
在实际使用中,可以根据需求适当的逆范式。
24. 取得最新一次添加记录(假设id为主键,并且是自增类型)所产生的id的函数是什么?
mysql_insert_id();如果上一查询没有产生AUTO_INCREMENT 的值,则mysql_insert_id()
返回 0。
25. php连接 mysql之后,如何设置 mysql的字符集编码为 utf8?
mysql_query(“set names utf8”);
26. php 访问数据库有哪几步?
主要有以下几个步骤:
-
连接数据库服务器:mysql_connect('host','user','password');
-
选择数据库:mysql_select_db(数据库名);
-
设置从数据库提取数据的字符集:mysql_query("set names utf8");
-
执行 sql 语句:mysql_query(sql 语句);
-
处理结果集
-
关闭结果集,释放资源:mysql_free_result($result);
-
关闭与数据库服务器的连接:mysql_close($link);
27. 在平常mysql优化方面,最基本的也是最重要的优化是()。(奇矩互动)
查询优化
28. 列出mysql数据库常用的几种类型HEAP、()、()。(奇矩互动)
MyISAM,innoDB
29. 请对于据select\fromtable example where((a and b)and c or(((a and b)and(c and d)))优化的语句。(奇矩互动)
题目多了一个括号,在 where 后面,但不影响题目的意思,可以将 sql 语句优化如下:
select * from table example where a and b and c
30. 解释MySQL外连接、内连接与自连接的区别(小米)
先说什么是交叉连接,交叉连接又叫笛卡尔积,它是指不使用任何条件,直接将一个表的所有记录和另一个表中的所有记录一一匹配。
内连接则是只有条件的交叉连接,根据某个条件筛选出符合条件的记录,不符合条件的记录不会出现在结果集中,即内连接只连接匹配的行。
而外连接其结果集中不仅包含符合连接条件的行,而且还会包括左表、右表或两个表中的所有数据行,这三种情况依次称之为左外连接,右外连接,和全外连接。
左外连接,也称左连接,左表为主表,左表中的所有记录都会出现在结果集中,对于那 些在右表中并没有匹配的记录,仍然要显示,右边对应的那些字段值以 NULL 来填充。
右外连接,也称右连接,右表为主表,右表中的所有记录都会出现在结果集中。 左连接和右连接可以互换,MySQL 目前还不支持全外连接。
31. 两条查询语句,一条是select * from table1 where id > 10and id 200 and id < 500,请尝试只写一条SQL 语句,完成相应的查询任务。(鑫众人云)
使用 union 语句,但有一个前提,即 table1 和 table2 的结构相同
SELECT * FROM table1 WHERE id > 10 AND id < 100 UNION ALL
SELECT * FROM table2 WHERE id > 200 AND id < 500
32. 写出你所知道的数据库。(亿邮)
MySQL,SQL Server, Oracle,Sybase, informix, DB2 等
33. 用户互为好友的 SNS 存储结构怎么设计。(亿邮)
首先是有用户表,如下:
CREATE TABLE user(
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, username VARCHAR(30) NOT NULL DEFAULT '' COMMENT '用户名', emailVARCHAR(50) NOT NULL DEFAULT '' COMMENT ' 邮箱 ', password CHAR(32) NOT NULL DEFAULT ''COMMENT '密码'
)engine=MyISAM charset=utf8 comment='用户表';
其次是用户间的关系,如下:
CREATE TABLE relation(
rel_id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, fuid INT UNSIGNED NOT NULL COMMENT '关注人的 id',
suid INT UNSIGNED NOT NULL COMMENT '被关注人的 id',
relation_type ENUM('S','D') NOT NULL DEFAULT 'S' COMMENT '关系,s 为关注,
d 表示为好友'
)engine=MyISAM charset=utf8 comment='用户关系表';
34. 假设现在有一个数据库服务器,服务器地址为192.168.0.110,用户名为root 密码为password 请使用 PHP 编写一个面向过程化的连接该数据库的脚本代码 (亿邮)
$conn = mysql_connect('192.168.0.110','root','password') or die('数据库连接失败');
35. 简述在 MySQL 数据库中 MyISAM 和 InnoDB 的区别 (亿邮)
区别主要有以下几个:
- 构成上,MyISAM 的表在磁盘中有三个文件组成,分别是表定义文件( .frm)、数据文件(.MYD)、索引文件(.MYI),而 InnoDB 的表由表定义文件(.frm)、表空间数据和日志文件组成。
- 安全方面,MyISAM 强调的是性能,其查询效率较高,但不支持事务和外键等安全性方面的功能,而 InnoDB 支持事务和外键等高级功能,查询效率稍低。
- 对锁的支持,MyISAM 支持表锁,而 InnoDB 支持行锁。
36. 现在有下面一个查询句 select \ from tabname where id=2 and password='abc’如何判断它是现在是最优的。(亿邮)
可以使用 explain select * from tabname where id=2 and password='abc’来分析其执行情况。
37. 请问如何在 Mysql 操作中如何写入 utf8 格式数据 (亿邮)
首先确保数据库中的表是基于 utf8 编码的,其次 php 文件是 utf8 编码,在执行 mysql 操作之前,执行 mysql_query(‘set names utf8’)操作,对于要操作的文本如果是 utf8 编码,则可以直接操作,如果是其它编码,则可以使用iconv 函数将其转化为 utf8 编码, 然后写入。
38. mysql 中 varchar 度是多少? 用什么类型的字段存储大文本? date 和datetime 和 timestamp 什么区别?怎么看数据库中有哪些 sql 正在执行? (卓望)
varchar 的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是65532 字节。在 varchar 存字符串的时候,第一个字节是空的,不存任何的数据,然后还需要两个字节来存放字符串的长度。所以有效长度就是 65535 - 1 - 2 =65532。
由字符集来确定,字符集分单字节和多字节,如果是单字节,如 latin1,则最多可以存放 65532 个字符,如果是多字节,如 GBK 则可以存放 32766 个字符,UTF8 则可以存放 21844个字符。
存储大文本可以使用 text 类型。
date 表示日期,其范围为 1000-01-01 ~ 9999-12-31
datetime 表示日期时间,其范围为 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
timestamp 是 unix 时 间 戳 的 日 期 时 间 表 示 方 式 , 其 范 围 较 小 为1970-01-01 00:00:00~2038-01-19 03:14:07 ,timestamp 具备自动初始化和自动更新功能。
查看数据库中正在执行的 sql 语句可以使用日志,也可以使用 show processlist 命令。
39. 现在有一个 mysql 数据库表visits 记录用户访问情况,表结构如下:
visits(
id int unsigned auto_increment,
user_id int unsigned comment ‘本次访问页面数’, visit_time timestamp comment‘本次访问开始时间’, primary key(id)
);
用户每访问过一次网站(从进入到离开),会增加一条记录。记录用户的ID(user_id),以及访问的页面总数。比如:
1)208,2,//208 这个用户访问 2 个页面
2)2073,3,
3)208,1,//208 用户访问了 1 个页面
(1). 请写一个SQL 语句挑出你是累计访问页面数最多的 10 个用户(user_id)和对应的访问页面数。
(2). 请写一个 SQL 语句,输出累计访问页面数分别等于 1,2,3,4,5,6,7,8,9,10 的唯一用户的数量,如果某个数量对应的用户数为 0,可以不输出。(嘀嗒团)
从题目的描述来看,表结构貌似有些问题,user_id 应为用户 ID,而不是访问页面数, 增加一个字段 pages 表示访问页面数。
查询访问页面数最多的 10 个用户的查询语句如下: SELECT user_id, sum(pages) as total FROM visits GROUP BY user_id ORDER BY total DESC LIMIT 10;
输出累计访问页面数分别等于 1,2,3,4,5,6,7,8,9,10 的唯一用户的数量的查询语句如下: SELECT total,count(user_id) FROM (SELECT user_id, sum(pages) AS total FROM visits
GROUP BY user_id) AS temp WHERE total IN (1,2,3,4,5,6,7,8,9,10) GROUP BY total ;
40. 简述存储过程的适用情况
当需要处理复杂的查询和运算时,可以使用存储过程。
从应用分层的原则,大量使用存储过程导致业务逻辑分散在 DB 和应用服务器层,不利于维护和更新。
总体来说,存储程序可以用,但要慎重,最好只用来维护,不用于业务逻辑和支撑高并 发高性能的东西。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。之前说过,PHP方面的技术点很多,也是因为太多了,实在是写不过来,写过来了大家也不会看的太多,所以我这里把它整理成了PDF和文档,如果有需要的可以
更多学习内容可以访问【对标大厂】精品PHP架构师教程目录大全,只要你能看完保证薪资上升一个台阶(持续更新)
以上内容希望帮助到大家,很多PHPer在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里入手去提升,对此我整理了一些资料,包括但不限于:分布式架构、高可扩展、高性能、高并发、服务器性能调优、TP6,laravel,YII2,Redis,Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等多个知识点高级进阶干货需要的可以免费分享给大家,需要的可以加入我的PHP技术交流群953224940
所属网站分类: 技术文章 > 博客
作者:肚子里的大哥
链接:http://www.phpheidong.com/blog/article/3144/f916720fab3c3fde278f/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力