

一次内存性能提升的项目实践
发布于2021-03-14 05:50 阅读(1457) 评论(0) 点赞(17) 收藏(1)
现代的开发语言除了C++以外,大部分都对内存管理做好了封装,一般的开发者根本都接触不到内存的底层操作。更何况现在各种优秀的开源组件应用越来越多,例如mysql、redis等,这些甚至都不需要大家动手开发,直接拿来用就好了。所以有些同学也会觉得作为应用层开发的同学没有学习的必要去学习底层。
但我想通过本文的实际案例告诉大家,哪怕不直接接触内存底层操作,就只是用一些开源的工具,如果你能理解底层的工作原理,你也能够用到极致。
用户访问历史读写需求
假如现在有这样一个业务需求,用户每次刷新都需要获得要消费的新数据,但是不能和之前访问过的历史重复。你可以把它和你经常在用的今日头条之类的信息流app联系起来。每次都要看到新的新闻,但是你肯定不想看到过去已经看过的文章。 这样在功能实现的时候,就必要保存用户的访问历史。当用户再来刷新的时候,首先得获取用户的历史记录,要保证推给用户的数据和之前的不重复。当推荐完成的时候,也需要把这次新推荐过的数据id记录到历史里。
为了适当降低实现复杂度,我们可以规定每个用户只要不和过去的一万条记录重复就可以了。这样每个用户最多只需要保存一万条历史id,如果存满了就把最早的历史记录挤掉。我们进一步具体化一下这个需求的几个关键点:
- 每个数据id是一个int整数来表示
- 每个用户要保存1万条id
- 每次用户刷新开始的时候需要将这1万条历史全部读取出来过滤一遍
- 每次用户刷新结束的时候需要将新访问过的10条写入一遍,如果超过1万需将最早的记录挤掉
可见,每次用户访问的时候,会涉及到一个1万规模的数据集上的一次读取和一次写入操作。
好了,需求描述完了,我们怎么样进行我们的技术方案的设计呢?相信你也能想到很多实现方案,我们今天来对比两个基于Redis下的存储方案在性能方面的优劣。
方案一:用Redis的list来存储
首先能想到的第一个办法就是用Redis的List来保存。因为这个数据结构设计的太适合上面的场景了。
List下的lrange命令可以实现一次性读取用户的所有数据id的需求。
$redis->lrange('TEST_KEY', 0,9999);
lpush命令可以实现新的数据id的写入,ltrim可以保证将用户的记录数量不超过1万条。
$redis->lpush('TEST_KEY', 1,2,3,4,5,6,7,8,9,10);
$redis->ltrim('TEST_KEY', 0,9999);
我们准备一个用户,提前存好一万条id。写入的时候每次只写入10条新的id,读取的时候通过lrange一次全部读取出来。进行一下性能耗时测试,结果如下。
Write repeats:10000 time consume:0.65939211845398 each 6.5939211845398E-5
Rrite repeats:10000 time consume:42.383342027664 each 0.0042383342027664
方案二:用Redis的string来存储
我能想到的另外一个技术方案就是直接用String来存。我们可以把1万个int表示的数据id拼接成一个字符串,用一个特殊的字符把他们分割开。例如:"100000_100001_10002"这种。 存储的时候,拼接一下,然后把这个大字符串写到Redis里。读取的时候,把大字符串整体读取出来,然后再用字符切割成数组来使用。
由于用string存储的时候,保存前多了一个拼接字符串的操作,读取后多了一步将字符串分割成数组的操作。在测试string方案的时候,为了公平起见,我们把需要把这两步的开销也考虑进来。
核心代码如下:
$userItems = array(......);
//写入
for($i=0; $i<$repeats; $i++){
$redis->set('TEST_KEY', implode('_', $userItems));
}
//读取
for($i=0; $i<10000; $i++){
$items = explode("_", $redis->get('TEST_KEY'));
}
耗时测试结果如下
Write repeats:10000 time consume:6.4061808586121 each 0.00064061808586121
Read repeats:10000 time consume:4.9698271751404 each 0.00049698271751404
结论
我们再直观对比下两个技术方案的性能数据。
| 写入耗时 | 读取耗时 | 总耗时 | |
|---|---|---|---|
| list | 0.066ms | 4.238ms | 4.304ms |
| string | 0.640ms | 0.496ms | 1.136ms |
基于list的方案里,写入速度非常快,只需要0.066ms,因为仅仅只需要写入新添加的10条记录就可以了,再加一次链表的截断操作,但是读取性能可就要慢很多了,超过了4ms。原因之一是因为读取需要整体遍历,但其实还有第二个原因。我们本案例中的数据量过大,所以Redis在内部实际上是用双端链表来实现的。.
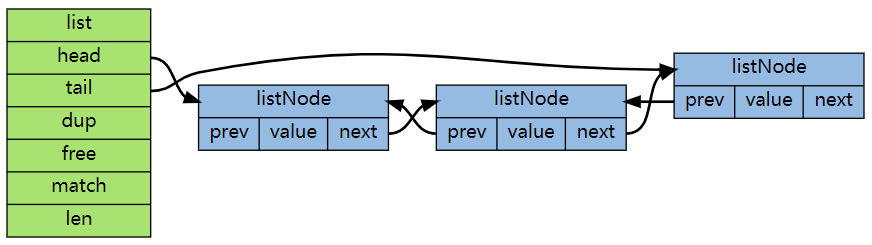
通过上图你可能看出来,链表是通过指针串起来的。大量的node之间极大可能是随机地分布在内存的各个位置上,这样你遍历整个链表的时候,实际上大概率会导致内存的随机模式下工作。
基于string方案在写入的时候耗时比list要高,因为每次都得需要将1万条全部写入一遍。但是读取性能却比list高了10倍,总体上耗时加起来大约只有方案一的1/4左右。为什么?我们再来看下redis string数据结构的内存布局
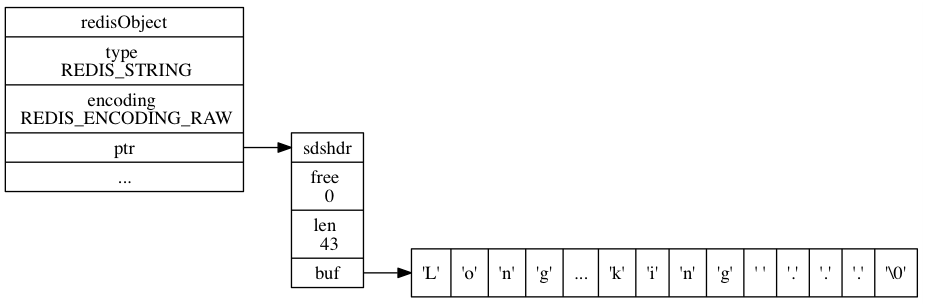
可见,如果用string来存储的话,不管用户的数据id有多少,访问将全部都是顺序IO。顺序IO的好处有两点:
- 1.一内存的顺序IO的耗时大约只是随机IO的1/3-1/4左右,
- 2.对于读取来说,顺序访问将极大地提升CPU的L1、L2、L3的cache命中率
所以如果你深入了内存的工作原理,哪怕你不能直接去操作内存,即使只是用一些开源的软件,你也能够将它的性能发挥到极致~

开发内功修炼之内存篇专辑:
- 1.带你深入理解内存对齐最底层原理
- 2.内存随机也比顺序访问慢,带你深入理解内存IO过程
- 3.从DDR到DDR4,内存核心频率其实基本上就没太大的进步
- 4.实际测试内存在顺序IO和随机IO时的访问延时差异
- 5.揭穿内存厂家“谎言”,实测内存带宽真实表现
- 6.NUMA架构下的内存访问延迟区别!
- 7.PHP7内存性能优化的思想精髓
- 8.一次内存性能提升的项目实践
- 9.挑战Redis单实例内存最大极限,“遭遇”NUMA陷阱!
我的公众号是「开发内功修炼」,在这里我不是单纯介绍技术理论,也不只介绍实践经验。而是把理论与实践结合起来,用实践加深对理论的理解、用理论提高你的技术实践能力。欢迎你来关注我的公众号,也请分享给你的好友~~~
原文链接:https://www.cnblogs.com/kfngxl/p/13917610.html
所属网站分类: 技术文章 > 博客
作者:php码农的美好生活
链接:http://www.phpheidong.com/blog/article/3030/2c7d2700d997fc6ad418/
来源:php黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力